OpenL Tablets BRMS Reference Guide¶
Preface¶
This preface is an introduction to the OpenL Tablets Reference Guide. The following topics are included in this preface:
Audience¶
This guide is mainly intended for analysts and developers who create applications employing the table based decision making mechanisms offered by OpenL Tablets technology. However, other users can also benefit from this guide by learning the basic OpenL Tablets concepts described herein.
Basic knowledge of Excel® is required to use this guide effectively. Basic knowledge of Java is required to follow the development related sections.
Related Information¶
The following table lists sources of information related to contents of this guide:
| Title | Description |
|---|---|
| OpenL Studio Guide | Document describing OpenL Studio, a web application for managing OpenL Tablets projects through a web browser. |
| https://openl-tablets.org/ | OpenL Tablets open source project website. |
Typographic Conventions¶
The following styles and conventions are used in this guide:
| Convention | Description |
|---|---|
| Bold | Represents user interface items such as check boxes, command buttons, dialog boxes, drop-down list values, field names, menu commands, menus, option buttons, perspectives, tabs, tooltip labels, tree elements, views, and windows. Represents keys, such as F9 or CTRL+A. Represents a term the first time it is defined. |
Courier |
Represents file and directory names, code, system messages, and command-line commands. |
| Select File > Save As | Represents a command to perform, such as opening the File menu and selecting Save As. |
| Italic | Represents any information to be entered in a field. Represents documentation titles. |
| \< > | Represents placeholder values to be substituted with user specific values. |
| Hyperlink | Represents a hyperlink. Clicking a hyperlink displays the information topic or external source. |
Introducing OpenL Tablets¶
This chapter introduces OpenL Tablets and describes its main concepts.
The following topics are included in this section:
- What Is OpenL Tablets?
- Basic Concepts
- System Overview
- Installing OpenL Tablets
- Tutorials and Examples
What Is OpenL Tablets?¶
OpenL Tablets is a Business Rules Management System (BRMS) and Business Rules Engine (BRE) based on tables presented in Excel documents. Using unique concepts, OpenL Tablets facilitates treating business documents containing business logic specifications as executable source code. Since the format of tables used by OpenL Tablets is familiar to business users, OpenL Tablets bridges a gap between business users and developers, thus reducing costly enterprise software development errors and dramatically shortening the software development cycle.
In a very simplified overview, OpenL Tablets can be considered as a table processor that extracts tables from Excel documents and makes them accessible from software applications.
The major advantages of using OpenL Tablets are as follows:
- OpenL Tablets removes the gap between software implementation and business documents, rules, and policies.
- Business rules become transparent to developers.
- OpenL Tablets verifies syntax and type errors in all project document data, providing convenient and detailed error reporting.
- OpenL Tablets can directly point to a problem in an Excel document.
- OpenL Tablets provides calculation explanation capabilities, enabling expansion of any calculation result by pointing to source arguments in the original documents.
- OpenL Tablets provides cross-indexing and search capabilities within all project documents.
- OpenL Tablets provides the ability to create compact and easily readable business rules that become a part of business documentation.
- Knowledge of Java or any other programming language is not required to create business rules with OpenL Tablets.
OpenL Tablets supports the .xls, .xlsx,and .xlsm file formats.
Basic Concepts¶
This section describes the following main OpenL Tablets concepts:
Rules¶
In OpenL Tablets, a rule is a logical statement consisting of conditions and actions. If a rule is called and all its conditions are true, then the corresponding actions are executed. Basically, a rule is an IF-THEN statement. The following is an example of a rule expressed in human language:
If a service request costs less than 1,000 dollars and takes less than 8 hours to execute, then the service request must be approved automatically.
Instead of executing actions, rules can also return data values to the calling program.
Tables¶
Basic information OpenL Tablets deals with, such as rules and data, is presented in tables. Tables within one project must be unique and it is denoted by table name and input parameters. Nevertheless, different versions of the same table can have the same name and input parameters.
Tables are referenced by calling their names.
Different types of tables serve different purposes. For more information on table types, see Table Types.
Projects¶
An OpenL Tablets project is a container of all resources required for processing rule related information. Usually, a project contains Excel files, which are called modules of the project, and optionally Java code, library dependencies, and other components. For more information on projects, see Working with Projects.
There can be situations where OpenL Tablets projects are used in the development environment but not in production, depending on the technical aspects of a solution.
System Overview¶
The following diagram displays how OpenL Tablets is used by different types of users.

OpenL Tablets overview
A typical lifecycle of an OpenL Tablets project is as follows:
- A business analyst creates an OpenL Tablets project in OpenL Studio.
- Optionally, development team may provide the analyst with a project in case of complex configuration.
-
The business analyst creates correctly structured tables in Excel files based on requirements and includes them in the project.
Typically, this task is performed through Excel or OpenL Studio in a web browser.
-
Business analyst performs unit and integration tests by creating test tables and performance tests on rules through OpenL Studio.
As a result, fully working rules are created and ready to be used.
-
Development team creates other parts of the solution and employs business rules directly through the OpenL Tablets engine or remotely through web services.
- Whenever required, a business user updates or adds new rules to project tables.
OpenL Tablets business rules management applications, such as OpenL Studio, Rules Repository, and OpenL Rule Services, can be set up to provide self-service environment for business user changes.
Installing OpenL Tablets¶
OpenL Tablets installation instructions are provided in OpenL Tablets Installation Guide > Deploying OpenL Studio. The development environment is required only for creating OpenL Tablets projects and launching OpenL Studio or OpenL Rule Services. If OpenL Tablets projects are accessed through OpenL Studio or web services, no specific software needs to be installed.
Tutorials and Examples¶
OpenL Tablets provides a number of preconfigured projects developed for new users who want to learn working with OpenL Tablets quickly.
These projects are organized into following groups:
Tutorials¶
OpenL Tablets provides a set of the tutorial projects demonstrating basic OpenL Tablets features starting from very simple and following with more advanced projects. Files in the tutorial projects contain detailed comments allowing new users to grasp basic concepts quickly.
To create a tutorial project, proceed as follows:
- To open Repository Editor, in OpenL Studio, in the top line menu, click the Repository item.
- Click the Create Project button
 .
. - In the Create Project from window, click the required tutorial name.
-
Click Create to complete.
The project appears in the Projects list of Repository Editor.

Creating tutorial projects
-
In the top line menu, click Rules Editor.
The project is displayed in the Projects list and available for usage. It is highly recommended to start from reading Excel files for examples and tutorials which provide clear explanations for every step involved.

Tutorial project in the OpenL Studio
Examples¶
In addition to tutorials, OpenL Tablets provides several example projects that demonstrate how OpenL Tablets can be used in various business domains.
To create an example project, follow the steps described in Tutorials, and in the Create Project from dialog, select an example to explore. When completed, the example appears in the OpenL Studio Rules Editor.
Creating Tables for OpenL Tablets¶
This chapter describes how OpenL Tablets processes tables and provides reference information for each table type used in OpenL Tablets.
The following topics are included in this chapter:
Table Recognition Algorithm¶
This section describes an algorithm of how the OpenL Tablets engine looks for supported tables in Excel files. It is important to build tables according to the requirements of this algorithm; otherwise, the tables are not recognized correctly.
OpenL Tablets utilizes Excel concepts of workbooks and worksheets, which can be represented and maintained in multiple Excel files. OpenL Tablets does not use any of Excel's formula capabilities though. Any calculations performed in OpenL Tablets are done using OpenL syntax, which is completely distinct from any formula syntax used by Excel. Excel worksheets can be named and arranged within one workbook in the order convenient to a user. Each worksheet, in its turn, is comprised of one or more tables. Workbooks can include tables of different types, each one supporting different underlying logic.
The general table recognition algorithm is as follows:
-
The engine looks into each spreadsheet and tries to identify logical tables.
Logical tables must be separated by at least one empty row or column or start at the very first row or column. Table parsing is performed from left to right and from top to bottom. The first populated cell that does not belong to a previously parsed table becomes the top-left corner of a new logical table.
-
The engine reads text in the top left cell of a recognized logical table to determine its type.
If the top left cell of a table starts with a predefined keyword, such table is recognized as an OpenL Tablets table.
The following are the supported keywords:
Keyword Table type Constants Constants Table ColumnMatch Column Match Table Data Data Table Datatype Datatype Table Environment Configuration Table Method Method Table Properties Properties Table Rules Decision Table Run Run Table SimpleLookup Simple Lookup Table SimpleRules Simple Rules Table SmartLookup Smart Lookup Table SmartRules Smart Rules Table Spreadsheet Spreadsheet Table TablePart Table Part TBasic or Algorithm TBasic Table Test Test Table All tables that do not have any of the preceding keywords in the top left cell are ignored. They can be used as comments in Excel files.
-
The engine determines the width and height of the table using populated cells as clues.
It is a good practice to merge all cells in the first table row, so the first row explicitly specifies the table width. The first row is called the table header.
Note: To put a table title before the header row, an empty row must be used between the title and the first row of the actual table.
Naming Conventions¶
The following conventions apply to the rule, field, and function names:
- The first character of the name must be Java letter, that is, a Unicode character, underscore, or dollar sign.
- The name must consist of Java letters and Java digits.
A Java digit is a collection of numbers from 0 to 9.

Examples of correct and incorrect rule table names
Table Types¶
OpenL Tablets supports the following table types:
- Decision Table
- Datatype Table
- Data Table
- Test Table
- Run Table
- Method Table
- Configuration Table
- Properties Table
- Spreadsheet Table
- TBasic Table
- Column Match Table
- Constants Table
- Table Part
Decision Table¶
A decision table contains a set of rules describing decision situations where the state of a number of conditions determines execution of a set of actions and returned value. It is a basic table type used in OpenL Tablets decision making.

Decision table example
The following topics are included in this section:
- Decision Table Structure
- Decision Table Interpretation
- Simple and Smart Rules Tables
- Simple and Smart Lookup Tables
- External Tables Usage in Smart Decision Tables
- Ranges and Arrays in Smart and Simple Decision Tables
- Rules Tables
- Collecting Results in Decision Table
- Local Parameters in Decision Table
- Transposed Decision Tables
- Representing Values of Different Types
- Using Calculations in Table Cells
- Referencing Attributes
- Calling a Table from Another Table
- Using Referents from Return Column Cells
- Using Rule Names and Rule Numbers in the Return Column
- Using References to Expressions
Decision Table Structure¶
An example of a decision table is as follows:
Decision table
The following table describes the full structure of a decision table with the Rules keyword:
| Row number |
Mandatory | Description |
|---|---|---|
| 1 | Yes | Table header, which has the following pattern: <keyword> <rule header> where <keyword> is either 'Rules' or 'DT' and <rule header> is a signature of a table with names and types of the rule and its parameters used to access the decision table and provide input parameters. |
| 2 | Yes | Row consisting of the following cell types: - Condition column header Identifies that the column contains a rule condition and its parameters. It must start with the “C” character followed by a number or be “MC1” for the 1st column with merged rows. If the condition has several parameters, the cell must be merged on all its parameter columns. Examples: C1, C5, C8, MC1 - Horizontal condition column header Identifies that the column contains a horizontal rule condition and its parameter (horizontal condition can have only one parameter). It must start with the “HC” character followed by a number. Horizontal conditions are used in lookup tables only. Examples: HC1, HC5, HC8 - Action column header Identifies that the column contains rule actions. It must start with the “A” character followed by a number. Examples: A1, A2, A5 - Return value column header Identifies that the column contains values to be returned to the calling program. A table can have multiple return columns, however, only the first fired non-empty value is returned. Example: RET1 All other cells in this row are ignored and can be used as comments. If a table contains action columns, the engine executes actions for all rules with true conditions. If a table has a return column, the engine stops processing rules after the first executed rule with true conditions and non-empty result found. |
| 3 | Yes | Row containing cells with expression statements for condition, action, and return value column headers. OpenL Tablets supports Java grammar enhanced with OpenL Tablets Business Expression (BEX) grammar features. For more information on the BEX language, see Appendix A: BEX Language Overview. In most cases, OpenL Tablets Business Expression grammar covers all the variety of expression statements and an OpenL user does not need to learn Java syntax. The code in these cells can use any objects and functions visible to the OpenL Tablets engine as elsewhere. For more information on enabling the OpenL Tablets engine to use custom Java packages, see Configuration Table. Purpose of each cell in this row depends on the cell above is as follows: - Condition column header Specifies the logical expression of the condition. It can reference parameters in the table header and parameters in cells below. The cell can contain several expressions, but the last expression must return a Boolean value. All condition expressions must be true to execute a rule. - Horizontal condition The same as Condition column header. - Action column header Specifies expression to be executed if all conditions of the rule are true. The expression can reference parameters in the rule header and parameters in the cells below. - Return value column header Specifies expression used for calculating the return value. The type of the last expression must match the return value specified in the rule header. The explicit return statement with the keyword “return” is also supported. This cell can reference parameters in the rule header and parameters in the cells below. |
| 4 | Yes | Row containing parameter definition cells. Each cell in this row specifies the type and name of parameters in the cells below it. Parameter name must be one word long. Parameter type must be one of the following: simple data types aggregated data types or Java classes visible to the engine arrays of the above types as described in Representing Arrays. |
| 5 | Yes | Descriptive column titles. The rule engine does not use them in calculations but they are intended for business users working with the table. Cells in this row can contain any arbitrary text and be of any layout that does not correspond to other table parts. The height of the row is determined by the first cell in the row. |
| 6 and below |
Yes | Concrete parameter values. Any cell can contain formula, a mathematical one or a rule call, instead of concrete value and calculate the value. This formula can reference parameters in the rule header and any parameters of condition columns in the return column. |
A user can merge cells of parameter values to substitute multiple single cells when the same value needs to be defined in these single cells. During rule execution, OpenL Tables unmerges these cells.
The additional Rule column with merged cells is used as the first column when the return value must be a list of values written in multiple rows of the same column, that is, a vertically arranged array. The Rule column determines the height of the result value list.

A table with the Rule column as the first column

Result in the vertically arranged array format
The rule column can be defined for rules tables and smart rules tables.
Decision Table Interpretation¶
Rules inside decision tables are processed one by one in the order they are placed in the table. A rule is executed only when all its conditions are true. If at least one condition returns false, all other conditions in the same row are ignored.
Blank parameter value cell of the condition is interpreted as a true condition and this condition is ignored for a particular rule row or column. If the condition column has several parameters, the condition with all its parameter cells blank is interpreted as a true condition.
Note: As OpenL Tablets returns the first true condition, it is a good practice to list all possible non-blank parameters and their combinations in case of multiple conditioning first, and then list the blank parameters.
Blank parameter value cell of the return/action column is ignored, the system does not calculate the return/action expression of the current rule and starts processing the next rule. If the return/action column has several parameters, all parameters cells need to be blank to ignore the rule.
If the empty return value is calculated by the expression, the system starts processing the next rule searching for a non-empty result.
The following example contains empty case interpretation. For Senior Driver, the marital status of the driver does not matter. Although there is no combination of Senior Driver and Single mode, the result value is 500 as for an empty marital status value.

Empty case interpretation in the Decision table
Simple and Smart Rules Tables¶
Practice shows that most of decision tables have a simple structure: there are conditions for input parameters of a decision table that check equality of input and condition values, and a return value. Because of this, OpenL Tablets have simplified decision table representations. A simplified decision table allows skipping condition and return columns declarations, and thus the table consists of a header, column titles and condition and return values, and, optionally, properties.
The following topics are included in this section:
- Simple Rules Table
- Smart Rules Table
- Multiple Return Columns in Smart Rules Tables
- Result of Custom Data Type in Smart and Simple Rules Tables
Simple Rules Table¶
A simplified decision table which has simple conditions for each parameter and a simple return can be easily represented as a simple rules table.
Unlike smart rules, a simple rule table uses all input parameters to associate them with condition columns in strict order, determined by simple logic, and using no titles. The value of the first column is compared with the value of the first input parameter, and so on. The value of the last column (return column) returns as a result. This means that input parameters must be in the same order as the corresponding condition columns, and the number of inputs must be equal to the number of conditions.
The simple rules table header format is as follows:
SimpleRules <Return type> RuleName(<Parameter type 1> parameterName1, (<Parameter type 2> parameterName 2….)
The following is an example of a simple rules table header:

Simple rules table example
Note: If a string value contains a comma, the value must be delimited with the backslash (\) separator followed by a comma. Otherwise, it is treated as an array of string elements as described in Ranges and Arrays in Smart and Simple Decision Tables.
Restrictions for a simplified decision table are as follows:
- Condition values must be of the same type or be an array or range of the same type as corresponding input parameters.
- Return values must have the type of the return type from the decision table header.
Smart Rules Table¶
A decision table which has simple conditions for input parameters and a direct return (without expression) can be easily represented as a smart rules table. Comparing to a simple rules table, a smart rules table type is used more frequently because smart rules are more flexible and cover wider range of business requirements.
The smart rules table header format is as follows:
SmartRules <Return type> RuleName(<Parameter type 1> parameterName1, (<Parameter type 2> parameterName 2…)

Smart rules table with simple return value
OpenL Tablets identifies which condition сolumns correspond to which input parameters by condition titles and parameter names. First of all, OpenL parses a parameter name and splits it into words, as it interprets a part starting with a capital letter as a separate word. Then it calculates the percentage of matching words in all columns and selects the column with the highest percentage of coincidence. If the analysis returns more than one result, OpenL throws an error and requires a more unique name for the column.
Note: OpenL Tablets matches input parameters or its fields to the conditions columns using the score. The score is calculated based on words used in parameter naming. If the particular parameter has the highest score for the particular condition, matching occurs. If several parameters have the same score, the system displays a warning message “Ambiguous matching of column titles to DT columns. Use more appropriate titles.” To overcome this issue and improve matching, use extended names for conditions.
In case of a custom datatype input, OpenL verifies all fields of the input object to match them separately with appropriate conditions using field names, in addition to input names, and column titles.

Smart rules table with object-input
OpenL is capable of matching abbreviations as well.
During rules execution, the system checks condition and input values on equality or inclusion and returns the result from the return columns, that is, the last columns identified as the result.
In the example above, the driverType value is compared with values from the Type of Driver column, the maritalStatus value is compared with the Marital Status column values, and the value from the Driver Premium column is returned as the result.
Note: To insure the system checks a condition with an appropriate input parameter, the user can ”hover” with a mouse over the column title and see the hint with this information in OpenL Studio.
If a string value of the condition contains a comma, the value must be delimited with the backslash (\) separator followed by the comma. Otherwise, it is treated as an array of string elements as described in Ranges and Arrays in Smart and Simple Decision Tables:

Comma within a string value in a Smart table
To define a range of values, two columns of the condition can be merged. In this case, the whole condition is interpreted asmin <= input parameter && input parameter < max.

Using min and max values for a range in the condition column
Special conditions not matching any particular input fields can be used in smart rules tables, for example, for validation rules definition. Column header for such condition must contain the word ‘true’. If there are other condition headers containing the word ‘true’, the name must be explicitly declared as “Is True?”. All values in such column are expressions or Boolean values. Such condition can also be used in the smart lookup tables.

Example of a condition that is a Boolean expression
If there is a horizontal condition of the Boolean type and the condition title is not a merged cell, it is preferable to use the title is true? instead of true because the title can be interpreted as a horizontal condition and cause wrong compilation.
A smart rule table can contain multiple and compound returns as described in Multiple Return Columns in Smart Rules Tables and use external tables as described in External Tables Usage in Smart Decision Tables.
Multiple Return Columns in Smart Rules Tables¶
A smart rules table can contain up to three return columns. If the first return column contains a non-empty result, it is returned, otherwise, the next return column is scanned until the non-empty result is found or the last return column is verified.
The following example illustrates a table with multiple return columns.

Example of a smart rules table with multiple return columns
In this example, the QuoteVolume rule has one condition, Coverage Type, and two return columns, Volume 1 and Volume 2. An example of the test table for this rule table is as follows.

Example of the test table for a rule table with multiple return columns
In the test table, Plan 1 is not of the Medical coverage type, so the second rule line is applied. In the test table, for the first test case, both History Premium and History Rate are provided, so Volume is calculated as 480 by the rule of Volume 1 column. For the second and third test case, one of inputs is missing, so Volume 1 returns an empty result, and the second return column calls another rule causing the result of 500 returned.
Note for experienced users: In case of a complex return object, only one compound return consisting of several return columns is allowed. All other returns can be defined using the formulas, that is, the new()operator or by calling another rule that returns the object of the corresponding type. For more information on complex return objects, see Result of Custom Data Type in Smart and Simple Rules Tables.
Result of Custom Data Type in Smart and Simple Rules Tables¶
A simplified rules table can return the value of compound type (custom data type) – the whole data object. To accomplish this, the user must make return column titles close to the corresponding fields of the object so the system can associate the data from the return columns with the returned object fields correctly. For more information on datatype tables, see Datatype Table.
In the example below, the rule VehicleDiscount determines the vehicles’s discount type and rate depending on air bags type and alarm indicator:

Smart rules table with compound return value
Note: To insure the system matches the return column with an appropriate return object field, the user can ”hover” over the column title and see the hint with this information in OpenL Studio.
Note: Return object fields are automatically filled in with input values if the return field name and input field name are matched.
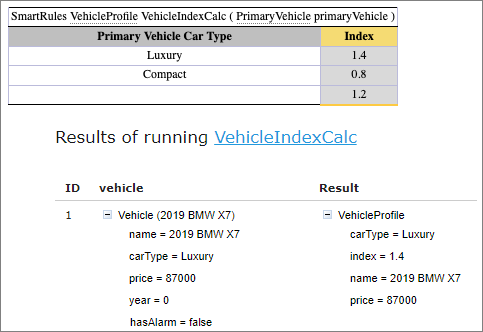
Return object fields automatically filled in with input values
If the rule returns the result of a very complex object (with nested objects inside), then there are several options for creating column titles:
- titles in one row with names that can be matched to the object fields unambiguously (the previously described approach) as shown in the example below, rule VehicleDiscount1;
- titles in several rows to define the hierarcy (structure) of the return object; in this case the user can merge cells associated with fields of a nested object as shown on the example below, rule VehicleDiscount2. Using this option, merging condition titles is required.

Smart rules tables with compound return value
Simple and Smart Lookup Tables¶
This section introduces lookup tables and includes the following topics:
- Understanding Lookup Tables
- Lookup Tables Implementation Details
- Simple Lookup Table
- Smart Lookup Table
Understanding Lookup Tables¶
A lookup table is a special modification of the decision table which simultaneously contains vertical and horizontal conditions and returns value on crossroads of matching condition values.
That means condition values can appear either on the left of the lookup table or on the top of it. The values on the left are called vertical and values on the top are called horizontal. Any lookup table must have at least one vertical and at least one horizontal value.

A lookup table example
Lookup Tables Implementation Details¶
This section describes internal OpenL Tablets logic.
At first, the table goes through parsing and validation.
- On parsing, all parts of the table, such as header, columns headers, vertical conditions, horizontal conditions, return column, and their values, are extracted.
- On validation, OpenL checks if the table structure is proper.
Then OpenL Tablets transforms a lookup table into a regular decision table internally and processes it as a regular decision table.
Simple Lookup Table¶
A lookup decision table with simple conditions that check equality of an input parameter and a condition value and a simple return can be easily represented as simple lookup table. This table is similar to simple rules table but has horizontal conditions. The number of parameters to be associated with horizontal conditions is determined by the height of the first column title cell.
The simple lookup table header format is as follows:
SimpleLookup <Return type> RuleName(<Parameter type 1> parameterName1, (<Parameter type 2> parameterName2,….)
The following is an example of a simple lookup table.

Simple lookup table example
Smart Lookup Table¶
A lookup decision table with simple conditions that check equality or inclusion of an input parameter with a condition value and a direct return (without expression) can be easily represented as a smart lookup table. This table resembles a smart rules table but has horizontal conditions.
The smart lookup table header format is as follows:
SmartLookup <Return type> RuleName(<Parameter type 1> parameterName1, (<Parameter type 2> parameterName2,….)

Smart lookup table example
Condition matching algorithm for smart lookup tables is the same as for smart rules tables. For vertical conditions, the system searches for input parameters suitable by title and then, for horizontal conditions, the system selects input parameters starting with the first of the rest inputs.
Boolean conditions can be used in the smart lookup tables as column headers. For more information on these conditions, see Smart Rules Table.
The number of horizontal conditions is determined by the height of the first column title cell. This means that title cells of the vertical conditions must be merged on all rows which go for horizontal conditions.
The following is an example of a smart lookup table with several horizontal conditions:

Smart lookup table with several horizontal conditions
OpenL Tablets supports titles for horizontal conditions. A horizontal condition title is defined either together with the last vertical condition header, separated by a slash character, or as a separate column after all vertical conditions.

Slash character in a red cell indicating that the cell contains condition titles for a vertical condition "Rating of Agency" and a horizontal condition "Total Assets

Algorithm identifying the third column as horizontal condition titles because the third column values are empty
If the height of the horizontal condition is 1, and there is a vertical condition with an empty column, the horizontal titles must be started with a slash /.
External Tables Usage in Smart Decision Tables¶
Conditions, returns, and actions declarations can be separated and stored in specific tables and then used in Smart Decision Tables via column titles. It allows using the Smart Table type for Decision rule even in case of the complicated condition or return calculation logic. Another benefit is that condition and return declarations can be reused in several rules, for example, Conditions table as a template. An example is as follows.

Using external conditions in a smart rules table
In this example, the first condition definition is taken from a separate Conditions table, an external table, and matched by column titles Agency and Rating of Agency. In OpenL Studio, such titles have links leading to the corresponding table. Other conditions are matched implicitly with input parameters by their names. In OpenL Studio, such titles have hints with all corresponding information.
Names of external tables have higher priority over input parameters. First of all, the engine checks if an external table with such name exists and if it is not found, the engine treats the column title as an input parameter. In the preceding example, OpenL Tablets first searches for an external table named Agency and finds it. Otherwise, the engine would treat Agency as input parameter.
External condition/return/action title must exactly match the title of the condition/return/action in the smart decision table. Inputs are matched by smart logic analyzing data types and names. Exact name matching is not required.
The external element table structure is as follows:
- The first row is the header containing the keyword, such as Actions, Conditions, or Returns, and optionally the name of the table.
- The first column under the header contains keyword, such as Inputs, Expression, Parameter, and Title.
-
Every column, starting from the second one, represents the element, that is, condition, action, and return definition.
Rows with the corresponding keyword contain the following information in the condition, action, and return definition rows:
Element Description Input Defines input parameters required for expression calculation of the element. It can be common for several expressions when cells are merged.
Input is optional for Returns and Actions.Expression Specifies the logical expression of the element. It must be merged accordingly if an element includes several parameters defined below. Parameter Stores parameter definition of the element. Title Provides a descriptive column title that is later used in the Smart Decision rule. -
The first column with keywords can be omitted if the default order Inputs – Expression – Parameter – Title is used.
Ranges and Arrays in Smart and Simple Decision Tables¶
Range and array data types can be used in simplified and smart rules and lookup tables. If a condition is represented as an array or range, the rule is executed for any value from that array or range. As an example, in the following image, there is the same Car Price for all regions of Belarus and Great Britain, so, using an array, three rows for each of these countries can be replaced by a single one as displayed in the following table.

Simple lookup table with an array
If a string value contains a comma, the value must be delimited with the backslash (\) separator followed by a comma as illustrated for Driver\, Passenger\, Side in the following example. Otherwise, it is treated as an array of string elements.

Comma within a string value in a Simple Rule table
The following example explains how to use a range in a simple rules table.

Simple rules table with a Range
OpenL looks through the Condition column, that is, ZIP Code, meets a range, which is not necessarily the first one, and defines that all the data in the column are IntRange, where Integer is defined in the header, Integer vehicleZip.
Simple and smart rules and smart lookup tables support using arrays of ranges. In the following example, the Z100-Z105, Z107, Z109 condition is a string range array where single elements Z107, Z109 are treated by system as ranges Z107-Z107, Z109-Z109.

Using arrays of ranges in a table
Note: String ranges are only supported in smart rules tables. For more information on range data types in OpenL Tablets, see Range Data Types.
Rules Tables¶
A rules table is a regular decision table with vertical and optional horizontal conditions where the structure of the condition and return columns is explicitly declared by a user by starting column headers with the characters specific for each column as described in Decision Table Structure.
By default, each row of the decision table is a separate rule. Even if some cells of condition columns are merged, OpenL Tablets treats them as unmerged. This is the most common scenario.
Vertical conditions are marked with the Cn and MC1 characters. The MC1 column plays the role of the Rule column in a table. It determines the height of the result value list. An example is as follows.
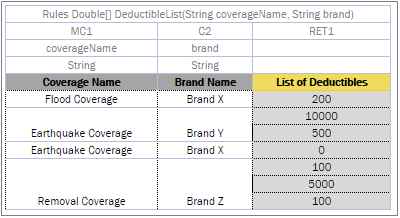
A Decision table with merged condition values
Earthquake Coverage for Brand Y and Brand X has a different list of values, so they are not merged although their first condition is the same.

A list of values as a result
The horizontal conditions are marked as HC1, HC2 and so on. Every lookup matrix must start from the HC or RET column. The first HC or RET column must go after all vertical conditions, such as C, Rule, and comment columns. There can be no comment column in the horizontal conditions part. The RET section can be placed in any place of the lookup headers row. HC columns do not have the Titles section.

A lookup table example
The first cell of column titles must be merged on all rows that contain horizontal condition values. The height of the titles row is determined by the first cell in the row. For example, see the Country cell in the previous example.
To use multiple column parameters for a condition, return, or action, merge the column header and expression cells. Use this approach if a condition cannot be presented as a simple AND combination of one-parameter conditions.

Example of the merged column header and expression cells
Any type of decision tables described previously, that is, Simple Rules, Smart Rules, Simple Lookup, and Smart Lookup, can be transformed into a Rules table with a detailed condition and return column declaration. Rules table is the most generic but least frequently used table type because other table types have simplified syntax and inbuilt logic satisfying specific business needs in a more user-friendly way.
Colors identify how values are related to conditions. The same table represented as a decision table is as follows:

Lookup table representation as a decision table
Collecting Results in Decision Table¶
A decision table returns only the first fired, non-empty result in common case. But there are business cases when all rules in a table must be checked and all results found returned. To do so, use:
Collectkeyword right before<Return type>in the table header for Simple and Smart rule table types;CRETas the return value column header for a regular decision table type;- Define
<Return type>as an array.
In the example below, rule InterestTable returns the list of interest schemes of a particular plan:

Collecting results in Smart and Simple rule table
In the following example, rule PriceTable collects car price information for desired specified country and/or ”make” of a car:


Collecting results in regular Decision table
Note for experienced users: Smart and Simple rule tables can return the collection of List, Set, or Collection type. To define a type of a collection element, use the following syntax: Collect as <Element type> <Collection type>for example, SmartRules Collect as String List Greeting (Integer hour).
Local Parameters in Decision Table¶
When declaring a decision table, the header must contain the following information:
- column type
- code snippet
- declarations of parameters
- titles
Recent experience shows that in 95% of cases, users add very simple logic within code snippet, such as just access to a field from input parameters. In this case, parameter declaration for a column is useless and can be skipped.
The following topics are included in this section:
Simplified Declarations¶
Case#1
The following image represents a situation when users must provide an expression and simple equal operation for condition declaration.
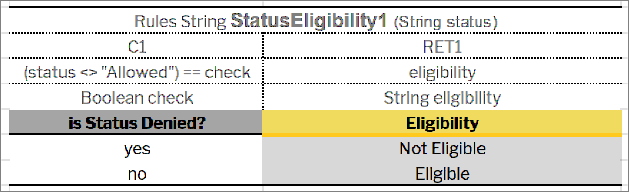
Decision table requiring an expression and simple equal operation for condition declaration
This code snippet can be simplified as displayed in the following example.

Simplified decision table
OpenL Engine creates the required parameter automatically when a user omits parameter declaration with the following information:
- The parameter name will be P1, where 1 is index of the parameter.
- The type of the parameter will be the same as the expression type.
In this example, it will be Boolean.
In the next step, OpenL Tablets will create an appropriate condition evaluator.
Note: The parameter name can be omitted in the situation when the contains(P1, expression value) operation for condition declaration is to be applied. The type of the parameter must be an array of the expression value type.

Simplified condition declaration
Case#2
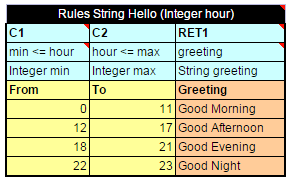
The following example illustrates the Greeting rule with the min \<= value and value \< max condition expression.
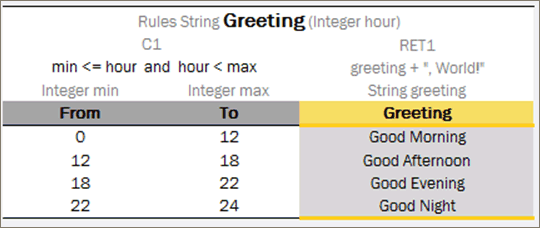
The Greeting rule
Instead of the full expression min \<= value and value \< max, a user can simply use value and OpenL Tablets automatically recognizes the full condition.

Simplified Greeting rule
Performance Tips¶
Time for executing the OpenL Tablets rules heavily depends on complexity of condition expressions. To improve performance, use simple or smart decision table types and simplified condition declarations.
To speed up rules execution, put simple conditions before more complicated ones. In the following example, simple condition is located before a more complicated one.

Simple condition location
The main benefit of this approach is performance: expected results are found much faster.
OpenL Tablets enables users to create and maintain tests to ensure reliable work of all rules. A business analyst performs unit and integration tests by creating test tables on rules through OpenL Studio. As a result, fully working rules are created and ready to be used.
For test tables, to test the rule table performance, a business analyst uses the Benchmark functionality. For more information on this functionality, see OpenL Studio Guide.
Transposed Decision Tables¶
Sometimes decision tables look more convenient in the transposed format where columns become rows and rows become columns. For example, an initial and transposed version of decision table resembles the following:

Transposed decision table
OpenL Tablets automatically detects transposed tables and is able to process them correctly.
Representing Values of Different Types¶
The following sections describe how to present some values – list or range of numbers, dates, logical values – in OpenL table cells. The following topics are included in this section:
Representing Arrays¶
For all tables that have properties of the enum[] type or fields of the array type, arrays can be defined as follows:
- horizontally
- vertically
- as comma separated arrays
The first option is to arrange array values horizontally using multiple subcolumns. The following is an example of this approach:
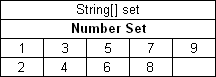
Arranging array values horizontally
In this example, the contents of the set variable for the first rule are [1,3,5,7,9], and for the second rule, [2,4,6,8]. Values are read from left to right.
The second option is to present parameter values vertically as follows:

Arranging array values vertically
In the second case, the boundaries between rules are determined by the height of the leftmost cell. Therefore, an additional column must be added to the table to specify boundaries between arrays.
In both cases, empty cells are not added to the array.
The third option is to define an array by separating values by a comma. If the value itself contains a comma, it must be escaped using back slash symbol “\”by putting it before the comma.

Array values separated by comma
In this example, the array consists of the following values:
- test 1
- test 3, 4
- test 2

Array values separated by comma. The second example
In this example, the array consists of the following values:
- value1
- value2
- value3
Two-dimensional arrays can be used in rules tables, where mixing values and expressions in arrays is allowed. An example is as follows:

Using two-dimensional arrays in a rules table
Representing Date Values¶
To represent date values in table cells, either Excel format or one of the following format must be used for the text:
* <year>-<month>-<date> (ISO 8601)
* <month>/<date>/<year> (US)
Note: In Excel, inputted text can be treated as a date and converted into Excel's date format. To prevent this, it's necessary to precede the text with an apostrophe to signify that it should be treated as text. Excel recognizes these values as simple text and does not automatically convert them into a date format.
The following are valid date value examples:
* 1980-07-12
* 5/7/1981
* 10/20/2002
OpenL Tablets recognizes all Excel date formats.
Representing Boolean Values¶
OpenL Tablets supports either Excel Boolean format or the following formats of Boolean values as a text:
- true, yes, y
- false, no, n
OpenL Tablets recognizes the Excel Boolean value, such as native Excel Boolean value TRUE or FALSE. For more information on Excel Boolean values, see Excel help.
Representing Range Types¶
In OpenL, the following data types are designed to work with ranges:
- IntRange
- DoubleRange
For more information on these data types used for ranges, see Range Data Types.

Decision table with IntRange
Note: Be careful with using Integer.MAX_VALUE in a decision table. If there is a range with the border max_numberequals to Integer.MAX_VALUE, for example, [100; 2147483647], it is not included to the range. This is a known limitation.
Using Calculations in Table Cells¶
OpenL Tablets can perform mathematical calculations involving method input parameters in table cells. For example, instead of returning a concrete number, a rule can return a result of a calculation involving one of the input parameters. The calculation result type must match the type of the cell. When editing tables in Excel files, start the text in the cells containing calculations with an apostrophe followed by =, and for the tables in OpenL Studio, start the text with =, without an apostrophe. Excel treats such values as a plain text.
The following decision table demonstrates calculations in table cells.

Decision table with calculations
The table transforms a twelve hour time format into a twenty four hour time format. The column RET1 contains two cells that perform calculations with the input parameter ampmHr.
Calculations use regular Java syntax, similar to the one used in conditions and actions.
Note: Excel formulas are not supported by OpenL Tablets. They are used as pre-calculated values.
Referencing Attributes¶
To address an attribute of an object in a rule, use the following syntaxes:
-
\<object name>.\<attribute name>

Defining an object attribute
-
\<attribute name> (\<object name>)

Defining an object attribute
The following rules apply:
- When a complex object is used as an input parameter in a rule, it is recommended to use a simplified reference without the input parameter name to address the direct attributes of this object.
- If input parameters do not have objects with the same attributes, the input parameter name can be omitted in the reference.
- If a complex object X is used as an input parameter in a rule, and this object has complex object Y as its attribute, when referencing object Y attributes in a rule, the input parameter name of the object X can be omitted.
An example of a redundant reference as follows:

A spreadsheet with a redundant reference
A full reference is redundant here and can be omitted as numberOfFamilies is an attribute of the policyEndorsementForm input paramter. The correct way to use the reference is as follows:

A spreadsheet with correct reference
An example of referencing an attribute of a complex object that is an attribute of a complex object input parameter is as follows:

A model describing complex objects structure and their attributes

A rule that is using reference to the attributes of the nested complex object
In this example, the input parameter in the rule is a complex object Policy, and one of its attributes is a complex object Plan. The Plan object includes its own attributes where one of them, Coverage, is a complex object as well.
Part of the rule logic is to check rate basis across all plans and coverages to make sure it is the same across all policy. To get to the rate basis attribute from the Policy object, go 2 levels down and omit the Policy level as Policy is already used as an input parameter: Plan (1st level down) > Coverage (2nd level down).
policyNumber, situsState do not have the policy.situsState reference as they are direct attributes of Policy. This means omitting input parameter reference of the top level.
The same syntax can be used in the array of objects, for example, cars.model or model(cars). The models of all cars in the received array are returned.
Calling a Table from Another Table¶
When one table’s results are required for calculation in another table, the first table can be called using ‘= TableName ( <inputParameter1 attribute name>, <inputParameter2 attribute name>, <inputParameterN attribute name> )where input parameters can be retrieved as follows:
- from the current table
- specifically declared as in the following ChildBenefitRate table example
- calculated using expressions, that is, formulas or by calling other rules
The input parameter attribute type is not specified when calling a nested rule.
In the following example, a nested rule table HeapedCommissionStrategy is called from the CommissionCalculation smart rule table.

Calling a nested rule table from a rule table
The return value type of the nested rule table must match the return value type of the current rule table.
Sometimes specific values must be sent to the nested table. In this case, input parameter values can be specified as follows:
- decalred in the quatation marks “” for String values
- set to true or false for Boolean values
- provided as a number for Double and Integer values
- set to null for empty values
For example, usually the detailed information about children is not included in the insurance policy and so default values are used to get the rates:


Declaring specific inputs when calling a nested rule table
Using Referents from Return Column Cells¶
When a condition value from a cell in the Return column must be called, specify the value by using $C<n>.<variable name>in the Return column.
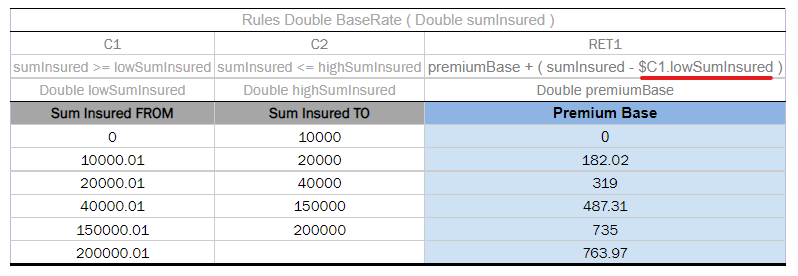
A Decision table with referents inside the Return column

Tracing Decision table with referents
Conditions, actions, and result parameters can be accessed from another condition, action, or result using simplified syntax. The same syntax can be also used for smart rules if external tables are used for condition, action, or result.

Accessing a condition parameter from a return expression by simplified syntax
Using Rule Names and Rule Numbers in the Return Column¶
Rule names and numbers can be used in the return expression to find out which rule is executed. $RuleId is an implicit number of the rule in the rule table. $Rule is used to get the rule name explicitly defined by the Rule column.
In the following rule example, the second rule row is executed, and rule ID #2 is stored in the priority field of the return:

Using $RuleId and $Rule in the rules table
Using References to Expressions¶
References to expressions can be used in decision tables. They can be referenced from table headers and within table body.
- $Expr.C1 is used to reference the expression for condition C1. To address action or return expression use RET1 and A1 respectively.

- $Expr.$C1.param1 is an expression defined as a value in a column for the param1 condition parameter. $C1 is optional. For instance, in the example below, parameter cond is the condition parameter for condition C2. It's important to use named parameters which is possible in decision tables of Rules type or when working with external conditions, actions, or returns in smart tables.
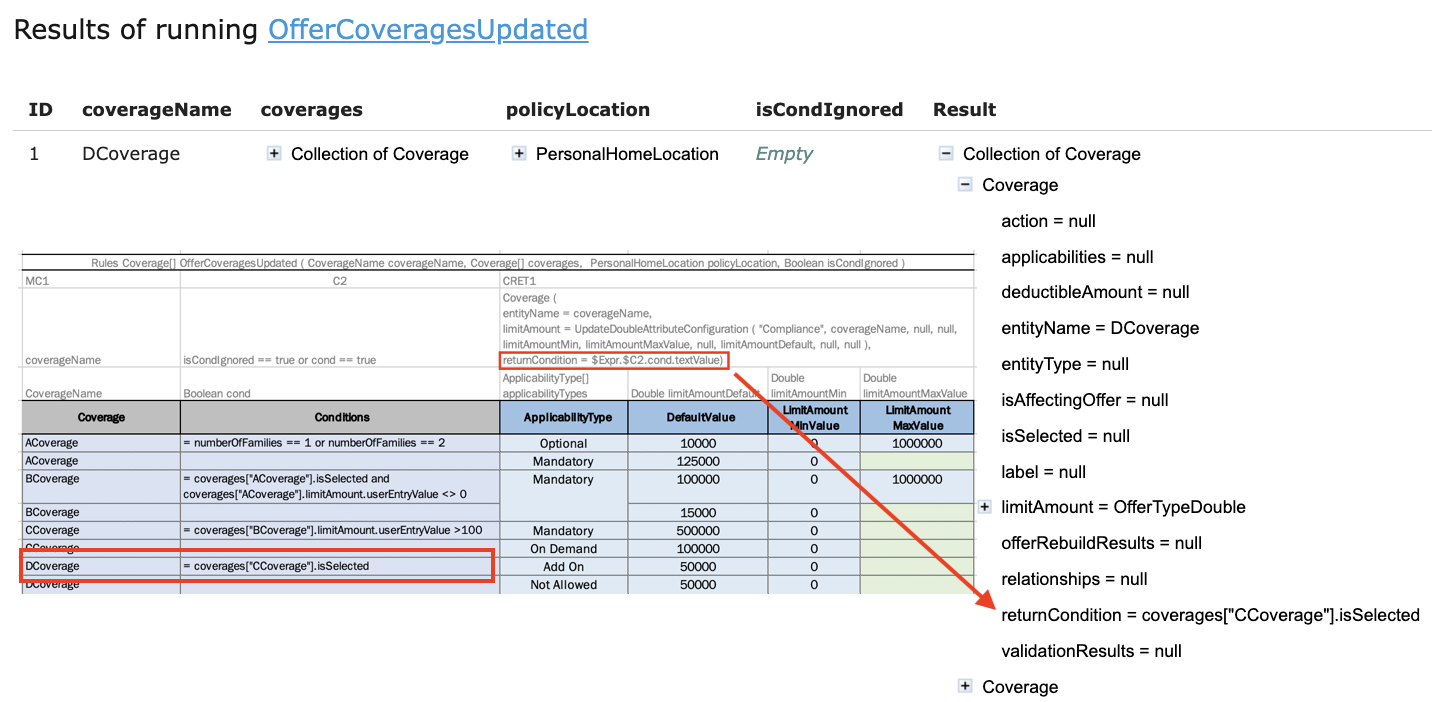
$Expr.C1, $Expr.$C1.param1 return the expression type that contains following attributes:
- ast - returns AST (Abstract Syntax Tree) tree for the expression
- textValue - returns a string representing an expression
Note: If a cell, which is expected to contain an expression or formula, is empty, it will return null.
Datatype Table¶
This section describes datatype tables and includes the following topics:
Introducing Datatype Tables¶
A Datatype table defines an OpenL Tablets data structure. A Datatype table is used for the following purposes:
- create a hierarchical data structure combining multiple data elements and their associated data types in hierarchy
- define the default values
- create vocabulary for data elements
A compound data type defined by Datatype table is called a custom data type. Datatype tables enable users to create their own data model which is logically suited for usage in a particular business domain.
For more information on creating vocabulary for data elements, see Vocabulary Data Types.
A Datatype table has the following structure:
- The first row is the header containing the Datatype keyword followed by the name of the data type.
-
Every row, starting with the second one, represents one attribute of the data type.
The first column contains attribute types, and the second column contains corresponding attribute names.
Note: While there are no special restrictions, usually an attribute type starts with a capital letter and attribute name starts with a small letter.
-
The third column is optional and defines default values for fields.
Consider the case when a hierarchical logical data structure must be created. The following example of a Datatype table defines a custom data type called Person. The table represents a structure of the Person data object and combines Person’s data elements, such as name, social security number, date of birth, gender, and address.

Datatype table Person
Note that data attribute, or element, address of Person has, by-turn, custom data type Address and consists of zip code, city, and street attributes.

Datatype table Address
The following example extends the Person data type with default values for specific fields.
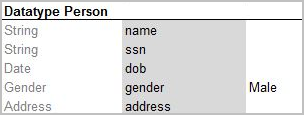
Datatype table with default values
The Gender field has the given value Male for all newly created instances if other value is not provided. If a value is provided, it has a higher priority over the default value and overrides it.
One attribute type can be used for many attribute names if their data elements are the same. For example, insuredGender and spouseGender attribute names may have Gender attribute type as the same list of values (Male, Female) is defined for them.
Note for experienced users: Java beans can be used as custom data types in OpenL Tablets. If a Java bean is used, the package where the Java bean is located must be imported using a configuration table as described in Configuration Table.
Consider an example of a Datatype table defining a custom data type called Corporation. The following table represents a structure of the Corporation data object and combines Corporation data elements, such as ID, full name, industry, ownership, and number of employees. If necessary, default values can be defined in the Datatype table for the fields of complex type when combination of fields exists with default values.

Datatype table containing value _DEFAULT_
FinancialData refers to the FinancialData data type for default values.
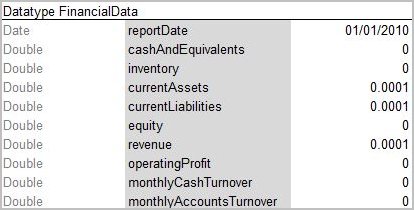
Datatype table with defined default values
During execution, the system takes default values from FinancialData data type.

Datatype table with default values
Note: For array types _DEFAULT_creates an empty array.
Note: It is strongly recommended to leave an empty column right after the third column with default values if such column is used. Otherwise, in case the data type has 3 or less attributes, errors occur due to transposed tables support in OpenL Tablets.
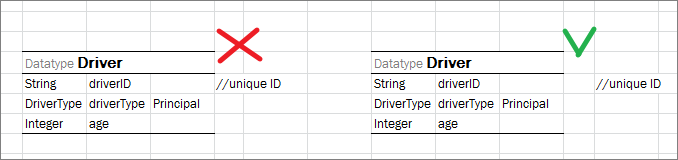
Datatype table with comments nearby
Note: A default value can be defined for String fields of the Datatype table by assigning the "" empty string.
For more information on using runtime context properties in Datatype tables, see Runtime Context Properties in Datatype Tables.
Datatype table output results can be customized the same way as spreadsheets as described in Spreadsheet Result Output Customization.
If a spreadsheet returns a data type rather than SpreadsheetResult and the attributes of this data type must be filtered, that is, included or excluded from the final output structure, attributes of this data type must be marked with ~ or *. An example is available in Introducing Datatype Tables.

Filtering data type attributes for the output structure
Inheritance in Data Types¶
In OpenL Tablets, one data type can be inherited from another one.
A new data type that inherits from another one contains all fields defined in the parent data type. If a child data type defines fields that are already defined in the parent data type, warnings, or errors, if the same field is declared with different types in the child and the parent data type, are displayed.
To specify inheritance, the following header format is used in the Datatype table:
Datatype <TypeName> extends <ParentTypeName>
Vocabulary Data Types¶
Vocabulary data types are used to define a list of possible values for a particular data type, that is, to create a vocabulary for data.
The vocabulary data type is created as follows:
-
The first row is the header.
It starts with the Datatype keyword, followed by the vocabulary data type name. The predefined data type is in angle brackets based on which the vocabulary data type is created at the end.
-
The second and following rows list values of the vocabulary data type.
The values can be of the indicated predefined data type only.
In the example described in Introducing Datatype Tables, the data type Person has an attribute gender of the Gender data type which is the following vocabulary data type.

Example of vocabulary datatype table with String parameters
Thus, data of Gender data type can only be Male or Female.
OpenL Tablets checks all data of the vocabulary data type one whether its value is in the defined list of possible values. If the value is outside of the valid domain, or defined vocabulary, OpenL Tablets displays an appropriate error. Usage of vocabulary data types provides data integrity and allows users to avoid accidental mistakes in rules.
Data Table¶
A data table contains relational data that can be referenced by its table name from other OpenL Tablets tables or Java code as an array of data.
Data tables are widely used during testing rules process when a user defines all input test data in data tables and reuses them in several test tables of a project by referencing the data table from test tables. As a result, different tests use the same data tables to define input parameter values, for example, to avoid duplicating data.
Data tables can contain data types supported by OpenL Tablets or types loaded in OpenL Tablets from other sources. For more information on data types, see Datatype Table and Working with Data Types.
The following topics are included in this section:
- Using Simple Data Tables
- Using Advanced Data Tables
- Specifying Data in Data Tables with List and Map Fields
- Specifying Data for Aggregated Objects
- Ensuring Data Integrity
Using Simple Data Tables¶
Simple data tables define a list of values of data types that have a simple structure.
-
The first row is the header of the following format:
Data <data type> <data table name>where data type is a type of data the table contains, it can be any predefined or vocabulary data type. For more information on predefined and vocabulary data types, refer to Working with Data Types and Datatype Table.
-
The second row is a keyword this.
- The third row is a descriptive table name intended for business users.
- In the fourth and following rows, values of data are provided.
An example of a data table containing an array of numbers is as follows.
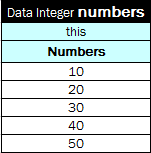
Simple data table
Using Advanced Data Tables¶
Advanced data tables are used for storing information of a complex structure, such as custom data types and arrays. For more information on data types, see Datatype Table.
-
The first row of an advanced data table contains text in the following format:
Data <data type> <data table name> -
Each cell in the second row contains an attribute name of the data type.
For an array of objects, the [i] syntax can be used to define an array of simple datatypes, and [i]. \<attributeName> to define an array of custom datatypes.
-
The third row contains attribute display names.
- Each row starting from the fourth one contains values for specific data rows.
The following diagram displays a datatype table and a corresponding data table with concrete values below it.

Datatype table and a corresponding data table
Note: There can be blank cells left in data rows of the table. In this case, OpenL Tablets considers such data as non-existent for the row and does not initialize any value for it, that is, there will be a null value for attributes or even null for the array of values if all corresponding cells for them are left blank.
There might be a situation when a user needs a Data table column with unique values, while other columns contain values that are not unique. In this case, add a column with the predefined _PK_ attribute name, standing for the primary key. It is called an explicit definition of the primary key.

A Data table with unique _PK_ column
If the _PK_ column is not defined, the first column of the table is used as a primary key. This is called an implicit definition of the primary key.

Referring from one Data table to another using a primary key
A user can call any value from a data table using the following syntax:
<datatable name>[<number of row>] Example: testcars[0]
<datatable name>["<value of PK>"] Example: testcars["BMW 35"]
Specifying Data in Data Tables with List and Map Fields¶
A list represents an ordered sequence of objects. Unlike array, a list can contain elements of any type. A map is a collection of key-value pairs. Each element of the map always has two values, a key and a value.
To define data table for lists and maps, use the following syntax:
-
for lists, [i]:\<element datatype>
[i] is order number
-
for maps, [“key”]:\<element datatype>
If a datatype table field is a list or a map, use the following syntax:
- for lists, \<attribute name>[i]:\<element datatype>
- for maps, \<attribute name>[“key”]:\<element datatype>
An example of the data table with a list of values used for zip codes is as follows:

Data table using a list field defined in the datatype table
Values of the list type can also be defined as a comma-separated list.
An example of the datatype table for this data table is as follows:

Datatype table with a list field
An example of the data table with a map of values used for zip codes is as follows:

Data table for the Map data type containing an aggregated object
An example of the datatype table for this table is as follows:

A datatype table for the address custom data type
Specifying Data for Aggregated Objects¶
Assume that the data, which values are to be specified and stored in a data table, is an object of a complex structure with an attribute that is another complex object. The object that includes another object is called an aggregated object. To specify an attribute of an aggregated object in a data table, the following name chain format must be used in the row containing data table attribute names:
<attribute name of aggregated object>.<attribute name of object>
To illustrate this approach, assume there are two data types, ZipCode and Address, defined:

Complex data types defined by Datatype tables
In the data type structure, the Address data type contains a reference to the ZipCode data type as its attribute zip. An example of a data table that specifies values for both data types at the same time is as follows.

Specifying values for aggregated objects
In the preceding example, columns Zip1 and Zip2 contain values for the ZipCode data type referenced by the Address aggregated data type.
Note: The attribute name chain can be of any arbitrary depth, for example, account.person.address.street.
If a data table must store information for an array of objects, OpenL Tablets allows defining attribute values for each element of an array.
The first option is to use the following format in the row of data table attribute names:
<attribute name of aggregated object>[i].<attribute name of object>
where i – sequence number of an element, starts from 0.
The following example illustrates this approach.

Specifying values for an array of aggregated objects using the flatten structure
The first policy, Policy1, contains two vehicles: Honda Odyssey and Ford C-Max; the second policy, Policy2, contains the only vehicle Toyota Camry; the third policy, Policy3, contains two vehicles: VW Bug and Mazda 3.
Note: The approach is valid for simple cases with an array of simple data type values, and for complex cases with a nested array of an array, for example, policy.vehicles[0].coverages[2].limit.
The second option is to leave the format as is, omitting the [] syntax in column definition
<attribute name of aggregated object>.<attribute name of object>,and define elements of an array in several rows, or in several columns in case of a transposed table.

Specifying values for an array of aggregated objects using the matrix structure
The following rules and limitations apply:
-
The cells of the first column, or aggregated object or test case keys, must be merged with all lines of the same aggregated object or test case.
A primary key column can be defined if data columns cannot be used for this purpose, for example, for complicated cases with duplicates.
-
The cells of the first column holding array of objects data, or array element keys, must be merged to all lines related to the same element, or have the same value in all lines of the element, or have the first value provided and other left blank thus indicating duplication of the previous value.
A primary key column can be defined, for example,
policy.vehicles._PK_,if data columns cannot be used for this purpose. Thus, the primary key cannot be left empty. -
In non-keys columns where only one value is expected to be entered, the value is retrieved from the first line of the test case and all other lines are ignored.
Even if these following lines are filled with values, no equality verification is performed.
-
Primary key columns must be put right before the corresponding object data.
In particular, all primary keys cannot be defined in the very beginning of the table.
Note: All mentioned formats of specifying data for aggregated objects are applicable to the input values or expected result values definition in the Test and Run tables.
Ensuring Data Integrity¶
If a data table contains values defined in another data table, it is important to specify this relationship. The relationship between two data tables is defined using foreign keys, a concept that is used in database management systems. Reference to another data table must be specified in an additional row below the row where attribute names are entered. The following format must be used:
> <referenced data table name> <column name of the referenced data table>
In the following example, the cities data table contains values from the states table. To ensure that correct values are entered, a reference to the code column in the states table is defined.

Defining a reference to another data table
If an invalid state abbreviation is entered in the cities table, OpenL Tablets reports an error.
The target column definition is not required if it is the first column or _PK_ column in the referenced data table. For example, if a reference is made to the name column in the states table, the following simplified reference can be used:
>states
If a data table contains values defined as a part of another data table, the following format can be used:
> <referenced data table name>.<attribute name> <column name>
The difference from the previous format is that an attribute name of the referenced data table, which corresponding values are included in the other data table, is specified additionally.
If <column name> is omitted, the reference by default is constructed using the first column or _PK_ column of the referenced data table.
In the following diagram, the claims data table contains values defined in the policies table and related to the vehicle attribute. A reference to the name column of the policies table is omitted as this is the first column in the table.

Defining a reference to another data table
Note: To ensure that correct values are provided, cell data validation lists can be used in Excel, thus limiting the range of values that can be entered.
Note: The same syntax of data integration is applicable to the input values or expected result values definition in the Test and Run tables.
Note: The attribute path can be of any arbitrary depth, for example, >policies.coverage.limit.
If the array is stored in the field object of the data table, array elements can be referred. An example is as follows.

Referring array elements in a test table
Test Table¶
This section describes test tables and context variables available in these tables. The following topics are included:
- Understanding Test Tables
- Context Variables Available in Test Tables
- Creating a Test Table for a Spreadsheet or Decision Table with SpreadsheetResult as Input Parameter
Understanding Test Tables¶
A test table is used to perform unit and integration tests on executable rule tables, such as decision tables, spreadsheet tables, and method tables. It calls a particular table, provides test input values, and checks whether the returned value matches the expected value.
For example, in the following diagram, the table on the left is a decision table but the table on the right is a unit test table that tests data of the decision table.
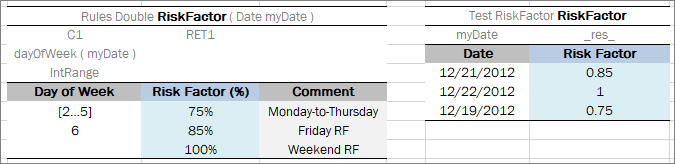
Decision table and its unit test table
A test table has the following structure:
-
The first row is the table header, which has the following format:
Test <rule table name> <test table name>Test is a keyword that identifies a test table. The second parameter is the name of the rule table to be tested. The third parameter is the name of the test table and is optional.
-
The second row provides a separate cell for each input parameter of the rule table followed by the _res_ column, which typically contains the expected test result values.
- The third row contains display values intended for business users.
- Starting with the fourth row, each row is an individual test case.
For more information on how to specify values of input parameters and expected test results of complex constructions, see Specifying Data for Aggregated Objects and Ensuring Data Integrity.
If a test table field is a list or a map, it can be used to create a data table or test table in the same way as for data tables as described in Specifying Data in Data Tables with List and Map Fields.
Note for experienced users: Test tables can be used to execute any Java method. In this case, a method table must be used as a proxy.
When a test table is called, the OpenL Tablets engine calls the specified rule table for every row in the test table and passes the corresponding input parameters to it.
If there are several rule tables with a different number of parameters but identical names and a test table is applicable to all rule tables, the test table is matched with the rule table which list of test input parameters matches exactly the list of rules input parameters in the test table. If there are extra parameters in all rule tables, or input parameters of multiple rule tables match test input parameters exactly, the Method is ambiguous message is displayed.
Application runtime context values are defined in the runtime environment. Test tables for a table, overloaded by business dimension properties, must provide values for the runtime context significant for the tested table. Runtime context values are accessed in the test table through the _context_ prefix. An example of a test table with the context value Lob follows:
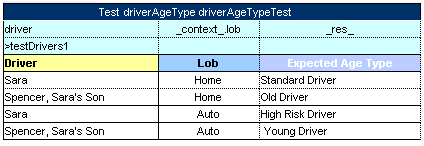
An example of a test table with a context value
For a full list of runtime context variables available, their description, and related Business Dimension versioning properties, see Context Variables Available in Test Tables.
Tests are numbered automatically. In addition to that, ID (id) can be assigned to the test table thus enabling a user to use it for running specific test tables by their IDs as described in OpenL Studio Guide > Defining the ID Column for Test Cases.
The _description_ column can be used for entering useful information.
The _error_ column of the test table can be used for a test algorithm where the error function is used. The OpenL Tablets Engine compares an error message to the value of the _error_ column to decide if test is passed.

An example of a test table with an expected error column
If OpenL Tablets projects are accessed and modified through OpenL Studio, UI provides convenient utilities for running tests and viewing test results. For more information on using OpenL Studio, see OpenL Studio Guide.
Context Variables Available in Test Tables¶
The following runtime context variables are used in OpenL Tablets and their values can be specified in OpenL test tables using syntax _context_.<context name>in a column header:
| Context | Context name in rule tables |
Type | Related versioning properties |
Property names in rule tables |
Description |
|---|---|---|---|---|---|
| Current Date | currentDate |
Date |
Effective / Expiration dates | effectiveDate, expirationDate |
Date on which the rule is performed. It is not equal to today’s date. |
| Request Date | requestDate |
Date |
Start / End Request dates | startRequestDate, endRequestDate |
Date when the rule is applied. |
| Line of Business | lob |
String |
LOB (Line of Business) | lob |
Line of business the rule is applied for. |
| US State | usState |
Enum |
US States | state |
US state where the rule is applied. |
| Country | country |
Enum |
Countries | country |
Country where the rule is applied. |
| US Region | usRegion |
Enum |
US Region | usregion |
US region where the rule is applied. |
| Currency | currency |
Enum |
Currency | currency |
Currency with which the rule is applied. |
| Language | lang |
Enum |
Language | lang |
Language in which the rule is applied. |
| Region | region |
Enum |
Region | region |
Economic region where the rule is applied. |
| Canada Province | caProvince | Enum |
Canada Province | caProvinces | Canada province of operation where the rule is applied. |
| Canada Region | caRegion | Enum |
Canada Region | caRegions | Canada region of operation where the rule is applied. |
| Nature | nature | String |
Nature | nature | User-defined business meaning value a rule is applied to. |
| locale | locale | java.lang.Locale |
n/a | n/a | Property commonly used for internationalization and localization purposes. |
For more information on how property values relate to runtime context values and what rule table is executed, see Business Dimension Properties and Rules Runtime Context.
Creating a Test Table for a Spreadsheet or Decision Table with SpreadsheetResult as Input Parameter¶
To create a test table for a spreadsheet or decision table that has another SpreadsheetResult as an input parameter, define the test table input as follows:
\<Input_name>.\$\<column_name>\$\<row_name>
\<Input_name> is the name of the input parameter. Spreadsheetresult, column_name, and row_name are names from the spreadsheet table used as input for a table to be tested.
Consider the following spreadsheet table.

Sample spreadsheet table
There is also one more spreadsheet table that uses fields from the first spreadsheet table.

Another spreadsheet table referencing fields of the first spreadsheet table
The following syntax is used to define the bankRatings value from SpreadsheetResult BankRatingCalculation as input for the test table.

A test table for a spreadsheet table with SpreadsheetResult as input parameter
Run Table¶
A run table calls a particular rule table multiple times and provides input values for each individual call. Therefore, run tables are similar to test tables, except they do not perform a check of values returned by the called method.
Note for experienced users: Run tables can be used to execute any Java method.
An example of a run method table is as follows.
Run table
This example assumes there is a rule append defined with two input parameters, firstWord and secondWord. The run table calls this rule three times with three different sets of input values.
A run table has the following structure:
-
The first row is a table header, which has the following format:
Run <name of rule table to call> <run table name>The run table name is optional.
-
The second row contains cells with rule input parameter names.
- The third row contains display values intended for business users.
- Starting with the fourth row, each row is a set of input parameters to be passed to the called rule table.
For more information on how to specify values of input parameters which have complex constructions, see Specifying Data for Aggregated Objects and Ensuring Data Integrity.
Method Table¶
A method table is a Java method described within a table. An example of a method table is as follows:

Method table
The first row is a table header, which has the following format:
<keyword> <return type> <table name> (<input parameters>)
where <keyword> is either Method or Code.
The second row and the following rows are the actual code to be executed. They can reference parameters passed to the method and all Java objects and tables visible to the OpenL Tablets engine. Code rows may not contain the <return> keyword. In this case, the last row of the table is returned as the table result.
This table type is intended for users experienced in programming in developing rules of any logic and complexity.
Configuration Table¶
This section describes the structure of the configuration table and includes the following topics:
Configuration Table Description¶
OpenL Tablets allows splitting business logic into multiple Excel files, or modules. There are cases when rule tables of one module need to call rule tables placed in another module. A configuration table is used to indicate module dependency.
Another common purpose of a configuration table is when OpenL Tablets rules need to use objects and methods defined in the Java environment. To enable use of Java objects and methods in Excel tables, the module must have a configuration table. A configuration table provides information to the OpenL Tablets engine about available Java packages.
A configuration table is identified by the keyword Environment in the first row. No additional parameters are required. Starting with the second row, a configuration table must have two columns. The first column contains commands, and the second column contains input strings for commands.
The following commands are supported in configuration tables:
| Command | Description |
|---|---|
dependency |
Adds a dependency module by its name. All data from that module becomes accessible in the current module. A dependency module can be located in the current project or its dependency projects. In simple words, this is how modules, often represented by Excel files, ‘communicate’ with each other if tables are split into different modules. |
import |
Imports the specified Java package, class, or library so that its objects and methods can be used in tables. |
language |
Provides language import functionality. |
extension |
Expands OpenL Tablets capabilities with external set of rules. After adding, external rules are complied with OpenL Tablets rules and work jointly. |
For more information on dependency and import configurations, see Project, Module, and Rule Dependencies.
Defining Dependencies between Modules in the Configuration Table¶
Often several or even all modules in the project have the same symbols in the beginning of their name. In such case, there are several options how to list several dependency modules in the Environment table:
- adding each dependency module by its name
- adding a link to all dependency modules using the common part of their names and the asterisk * symbol for the varying part
- adding a link to several dependency modules using the question mark ? symbol to replace one symbol anywhere in the name
All modules that have any letter or number at the position of the question mark symbol will be added as dependency.
The second option, that is, using the asterisk symbol after the common part of names, is considered a good practice because of the following reasons:
- Any new version of dependency module is not omitted in future and requires no changes to the configuration table.
- The configuration table looks simpler.

Configuration table with dependency modules added by their name

Configuration table with link to all dependency modules
Note: When using the asterisk * symbol, if the name of the module where dependency is defined matches the pattern, this module is automatically excluded from dependent modules to avoid circular dependencies.
The following example illustrates how displaying dependency modules in the configuration table impacts resulting values calculation. The following modules are defined in the project for an auto insurance policy:
Auto-Rating Algorithm.xlsxAuto-Rating-Domain Model.xlsxAuto-Rating-FL-01012016.xlsxAuto-Rating-OK-01012016.xlsxAuto-Rating Test Data.xlsx
The purpose of this project is to calculate the Vehicle premium. The main algorithm is located in the Auto-Rating Algorithm.xlsx Excel file.

Rule with the algorithm to calculate the Vehicle premium
This file also contains the configuration table with the following dependency modules:
| Module | Description |
|---|---|
Auto-Rating-Domain Model.xlsx |
Contains the domain model. |
Auto-Rating-FL-01012016.xlsx |
Contains rules with the FL state specific values used in the premium calculation. |
Auto-Rating-OK-01012016.xlsx |
Contains rules with the OK state specific values. |
All these modules have a common part at the beginning of the name, Auto-Rating-.
The configuration table can be defined with a link to all these modules as follows:

Configuration table in the Auto-Rating Algorithm.xlsx file
Note: The dash symbol - added to the dependency modules names in a common part helps to prevent inclusion of dependency on Auto-Rating Algorithm itself.
Properties Table¶
A properties table is used to define the module and category level properties inherited by tables. The properties table has the following structure:
| Element | Description |
|---|---|
| Properties | Reserved word that defines the type of the table. It can be followed by a Java identifier. In this case, the properties table value becomes accessible in rules as a field of such name and of the TableProperties type. |
| scope | Identifies levels on which the property inheritance is defined. Available values are as follows: - Module Identifies properties defined for the whole module and inherited by all tables in it. There can be only one table with the Module scope in one module.  A properties table with the Module level scope - Category Identifies properties applied to all tables where the category name equals the name specified in the category element. By default, a category name equals to the worksheet name.  A properties table with the Category level scope |
| category | Defines the category if the scope element is set to Category. If no value is specified, the category name is retrieved from the sheet name. |
| Module | Identifies whether properties can be overridden and inherited on the module level. |
Spreadsheet Table¶
In OpenL Tablets, a spreadsheet table is an analogue of the Excel table with rows, columns, formulas, and calculations as contents even though none of Excel formulas are used in OpenL Tables. Spreadsheets can also call decision tables or other executable tables to make decisions on values, and based on those, make calculations.
The format of the spreadsheet table header is as follows:
Spreadsheet SpreadsheetResult <table name> (<input parameters>)
or
Spreadsheet <return type> <table name> (<input parameters>)
The following table describes the spreadsheet table header syntax:
| Element | Description |
|---|---|
| Spreadsheet | Reserved word that defines the type of the table. |
| SpreadsheetResult | Type of the return value. SpreadsheetResult returns the calculated content of the whole table. |
| \<return type> | Data type of the returned value. If only a single value is required, its type must be defined here as a return data type and calculated in the row or column named RETURN, or in the last row or column if the RETURN keyword is not defined. |
| \<table name> | Valid name of the table as for any executable table. |
| \<input parameters> | Input parameters as for any executable table. |
The first column and row of a spreadsheet table, after the header, make the table column and row names. Values in other cells are the table values. An example is as follows.
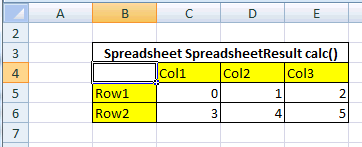
Spreadsheet table organization
It is common practice to create a spreadsheet table with two columns only: Step where business step names are specified, and Formula containing action description. A spreadsheet table cell can contain:
- simple values, such as a string or numeric values
- values of other data types
- formulas, which can be mathematical expressions, rule calls, and other operators or functions
Formulas are preceded by an apostrophe followed by = if editing a table in Excel, or directly with = if editing a table in OpenL Studio.
- another cell value or a range of another cell values referenced in a cell formula
The following table describes how a cell value can be referenced in a spreadsheet table.
| Cell name | Reference | Description |
|---|---|---|
$columnName |
By column name. | Used to refer to the value of another column in the same row. |
$rowName |
By row name. | Used to refer to the value of another row in the same column. |
$columnName$rowName |
Full reference. | Used to refer to the value of another row and column. |
For more information on how to specify a range of cells, see Using Ranges in Spreadsheet Table. Below is an example of a spreadsheet table with different calculations for an auto insurance policy. Table cells contain simple values, formulas, references to the value of another cell, and other information.
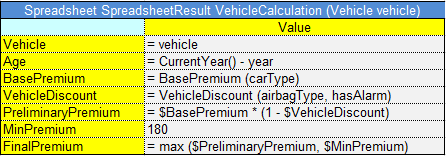
Spreadsheet table with calculations as content
The data type for each cell can be determined by OpenL Tablets automatically or it can be defined explicitly for each row or column. The data type for a whole row or column can be specified using the following syntax:
<column name or row name> : <data type>
Note: If both column and row of the cell have a data type specified, the data type of the column is taken.
In OpenL Rule Services, spreadsheet output can be customized by adding or removing rows and columns to display as described in Spreadsheet Result Output Customization.
The following topics are included in this section:
- Parsing a Spreadsheet Table
- Accessing Spreadsheet Result Cells
- Using Ranges in Spreadsheet Table
- Auto Type Discovery Usage
- Custom Spreadsheet Result
- Spreadsheet Result Output Customization
- Testing Spreadsheet Result
Parsing a Spreadsheet Table¶
OpenL Tablets processes spreadsheet tables in two different ways depending on the return type:
- A spreadsheet returns the result of SpreadsheetResult data type.
- A spreadsheet returns the result of any other data type different from SpreadsheetResult.
In the first case, users get the value of SpreadsheetResult type that is an analog of result matrix. All calculated cells of the spreadsheet table are accessible through this result. The following example displays a spreadsheet table of this type.
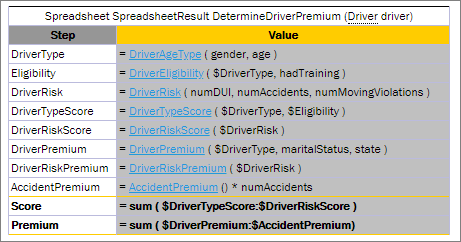
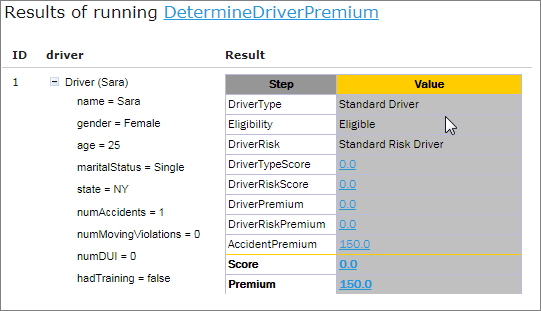
Spreadsheet table returns the SpreadsheetResult datatype
In the second case, the returned result type is a data type as in all other rule tables, so there is no need for SpreadsheetResult in the rule table header. The value of the last row, or the latest one if there are several columns, is returned. OpenL Tablets calculates line by line as follows:
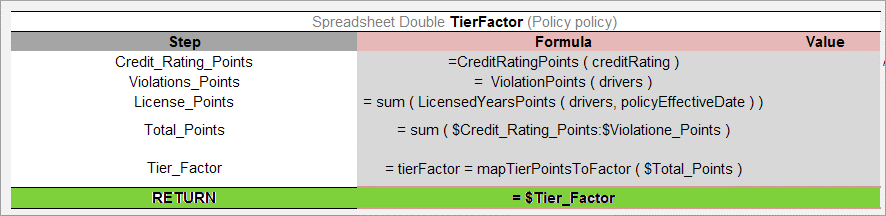
Spreadsheet table returning a single value
Accessing Spreadsheet Result Cells¶
A value of the SpreadsheetResult type means that this is actually a table, or matrix, of values which can be of different types. A cell is defined by its table column and row. Therefore, a value of a particular spreadsheet cell can be accessed by cell’s column and row names as follows:
<spreadsheet result variable>.$<column name>$<row name>
or
$<column name>$<row name>(<spreadsheet result variable>)
If a spreadsheet has one column only, besides the column holding step names, spreadsheet cells can be referenced by row names. If there is one row and multiple columns, a cell can be referenced by the column name.
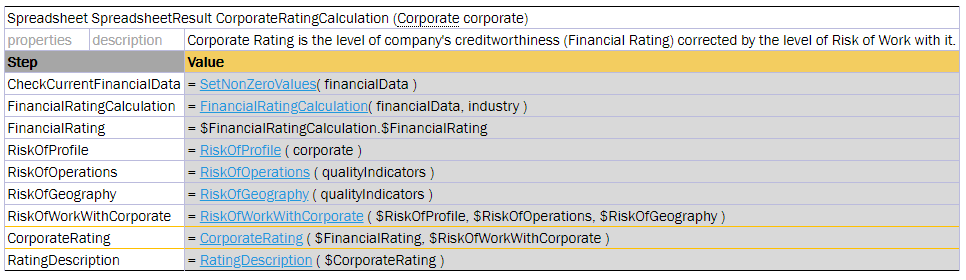
Referencing a cell by a row name
The same functionality is available in test tables as described in Testing Spreadsheet Result.
The spreadsheet cell can also be accessed using the getFieldValue(String <cell name>)function, for instance, (Double) $FinancialRatingCalculation.getFieldValue ("$Value$FinancialRating"). This is a more complicated option.
Note: If the cell name in columns or rows contains forbidden symbols, such as space or percentage, the cell cannot be accessed. For more information on symbols that are not allowed, see Java method documentation.
Using Ranges in Spreadsheet Table¶
The following syntax is used to specify a range in a spreadsheet table:
$FirstValue:$LastValue
An example of using a range this way in the TotalAmount column is as follows.
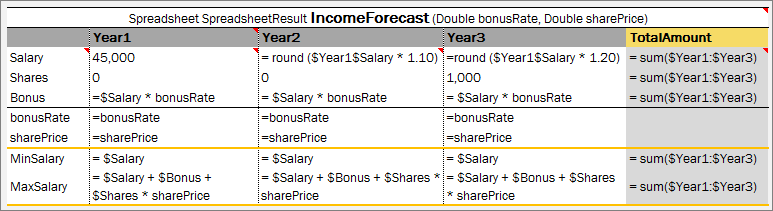
Using ranges of Spreadsheet table in functions
Note: In expressions, such as min/max($FirstValue:$LastValue), there must be no space before and after the colon ':' operator.
Note: It is impossible to make math operations under ranges which names are specified with spaces. Please use step names without spaces.
Auto Type Discovery Usage¶
OpenL Tablets determines the cell data type automatically without its definition for a row or column. A user can turn on or off this behavior using the autotype property. If any row or column contains explicit data type definition, it supersedes automatically determined data type. The following example demonstrates that any data type can be correctly determined in auto mode. A user can put the mouse cursor over the “=” symbol to check the type of the cell value in OpenL Studio.
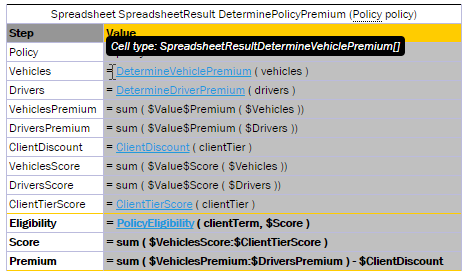
Auto Type Discovery Property Usage inside Spreadsheet table
The SpreadsheetResult cell type is automatically determined if a user refers to it from another table according to the following logic:
- Search for a cell with the same name is performed through all spreadsheets, and its type is set for the current cell.
- If several spreadsheets have cells with the same name but different types, the nearest common type is set for the current cell.
Recommendation: To ensure the system identifies types correctly, within the project, use data of the same type in the steps with the same name.
This logic also works when a user explicitly defines the type of the value as common SpreadsheetResult, for instance, in the following input parameter definition:

Defining the value type as SpreadsheetResult
However, there are several limitations of auto type discovering when the system cannot possibly determine the cell data type:
-
Type identification algorithm is not able to properly identify the cell type when a cell refers to another cell with the same name because of occurred circular dependencies.
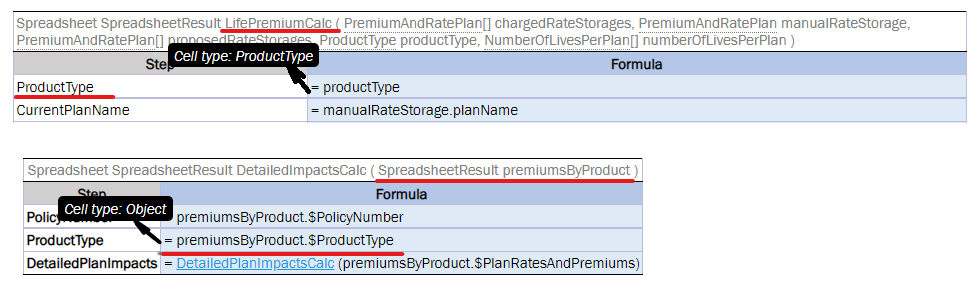
Limitation for referring to another cell with the same name
-
A user explicitly defines the return type of other Rules tables, such as Decision tables, as common SpreadsheetResult as follows:

Explicitly defining the return type of other rules tables
The type of undefined cells must be explicitly defined as a custom spreadsheet result type or any other suitable type to avoid uncertain Object typing.
-
There is a circular dependency in a spreadsheet table calling the same spreadsheet rule itself in a cell. This cell type must be explicitly defined to allow correct auto type discovering of the whole spreadsheet table as follows:
Defining a cell type explicitly
Custom Spreadsheet Result¶
Usage of spreadsheet tables that return the SpreadsheetResult type is improved by having a separate type for each such spreadsheet table, that is, custom SpreadsheetResult data type, which is determined as follows:
SpreadsheetResult<Spreadsheet table name>
Custom SpreadsheetResult data type is automatically generated by a system and substitutes common SpreadsheetResult type. This provides the following advantages:
-
The system understands the structure of the spreadsheet result, that is, knows names of columns and rows, and data types of cell values.
In other words, there is no need to indicate a data type when accessing the cell.
-
Test spreadsheet cell can be of any complex type.
For more information on test spreadsheet result, see Testing Spreadsheet Result.
To understand how this works, consider the following spreadsheet.
An example of a spreadsheet
The return type is SpreadsheetResult, but it becomes SpreadsheetResultCoveragePremium data type. Now it is possible to access any calculated cell in a very simplified way without indicating its data type, for example, as displayed in the following figure.
Calling Spreadsheet cell
In this example, the spreadsheet table cell is accessed from the returned custom spreadsheet result.
There is no need to specify a custom SpreadsheetResult data type in the header of the spreadsheet table itself. The return data type is still SpreadsheetResult. Only when passing such spreadsheet as input to another table, the full name must be declared. For example, if the CensusEmployeeCalc spreadsheet is an input parameter for the ClaimCostCalculation spreadsheet, (SpreadsheetResultCensusEmployeeCalc censusCalc) must be included in the list of inputs.
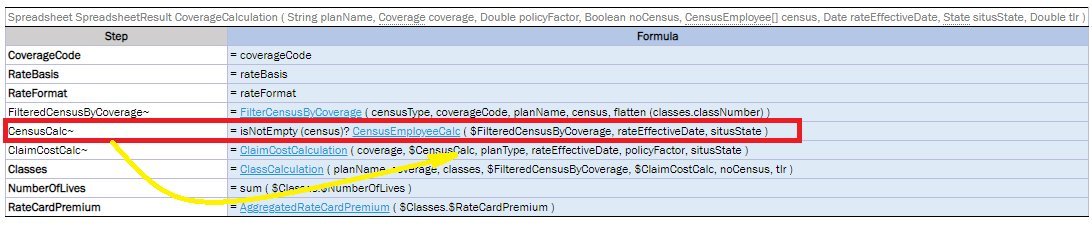
Example of calling a spreadsheet to be used as input
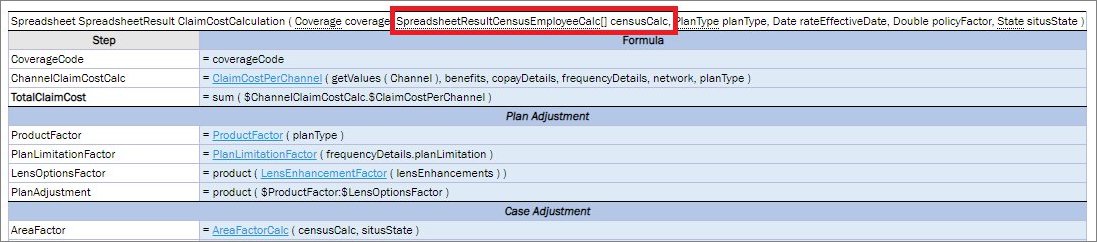
Using a custom spreadsheet as an input parameter
United Spreadsheet Result¶
The combined SpreadsheetResult type is used when the rules table returns different SpreadsheetResults to prevent the cell type loss. The united SpreadsheetResult is returned in the following cases:
- A rule returns SpreadsheetResult.
-
Different spreadsheets are called in a ternary operation.
For more information on ternary operations, see Ternary Operator.
-
The array of SpreadsheetResult is created by united spreadsheet cells (\$Step1:\$Step10).

Example of a rule returning a united spreadsheet result
A united spreadsheet result can be used as an input parameter.
- If the united spreadsheet result is generated as a result of the rule returning spreadsheet results, the input parameter has the (SpreadsheetResultSpreadsheetName inputValueName) format. Example: SpreadsheetResultClaimCost claimCostCalc.
- If the united spreadsheet result is generated as a result of the ternary operation of by uniting spreadsheet cells, the input parameter has the (SRSpr1 & SRSpr2 ruleName) format.
An example is as follows:
Rate = coverage.fundingType == "FullyInsured" ? RateCalculation ( rateBasis, $TotalVolume, $NumberOfLives, $MonthlyPremiumPreliminary) : ASORate (calculatedClass.$TotalNetClaimCost, TLR, $NumberOfLives, coverage)
If passing results of the Rate step to another rule, the type of the spreadsheet defined in this step is a united spreadsheet SRRateCalculation & SRASORate.
Spreadsheet Result Output Customization¶
To simplify integration with OpenL rules, customize serialization output of SpreadsheetResult objects by adding or removing steps or columns from spreadsheet result output.
- To identify steps or columns to be returned in the SOAP/REST response, mark them using the * asterisk symbol.
- To ensure that certain steps or columns are not included in output, mark them with the ~ tilde symbol.
Consider the following spreadsheets.
Spreadsheets example
For these spreadsheets, output result is as follows.
{
"PremiumCalc": {
"PolicyID": "P1",
"VehiclesPremiumCalc": [
{
"VehicleID": "V1",
"CoverageCalculation": [
{
"CoverageType": "Bodily Injury",
"BaseRate": 150,
"VehicleYearFactor": 1.35,
"MileageFactor": 1.19,
"CoverageTotal": 240.98
},
{
"CoverageType": "Property Damage",
"BaseRate": 130,
"VehicleYearFactor": 1.35,
"MileageFactor": 1.19,
"CoverageTotal": 208.85
}
],
"VehicleCoveragesSum": 449.83,
"VehicleDiscounts": 0.08,
"VehicleDiscountsAmount": 36,
"TotalVehiclePremium": 413.83
}
],
"DriversPremiumCalc": [
{
"DriverID": "D1",
"DriverAge": 44,
"AgeRate": 1,
"RiskAdjustment": 1,
"ConvictedDriverFactor": 1.2,
"TotalDriverPremium": 1.2
}
],
"PolicyPremiumSubtotal": 415.03,
"CustomerDiscount": 0.12,
"TotalPolicyPremium": 365.23
}
}
In the following example, some steps are marked with the asterisk to be included in the output.
Example of spreadsheets with mandatory steps
An output for these tables is as follows:
{
"PremiumCalc": {
"PolicyID": "P1",
"VehiclesPremiumCalc": [
{
"VehicleID": "V1",
"CoverageCalculation": [
{
"CoverageType": "Bodily Injury",
"CoverageTotal": 240.98
},
{
"CoverageType": "Property Damage",
"CoverageTotal": 208.85
}
],
"TotalVehiclePremium": 413.83
}
],
"DriversPremiumCalc": [
{
"DriverID": "D1",
"TotalDriverPremium": 1.2
}
],
"TotalPolicyPremium": 365.23
}
}
Within a project, different tables can contain ~ or * markings. Using one or another depends on whether a user needs more steps to include or exclude into the final result. An example is as follows.
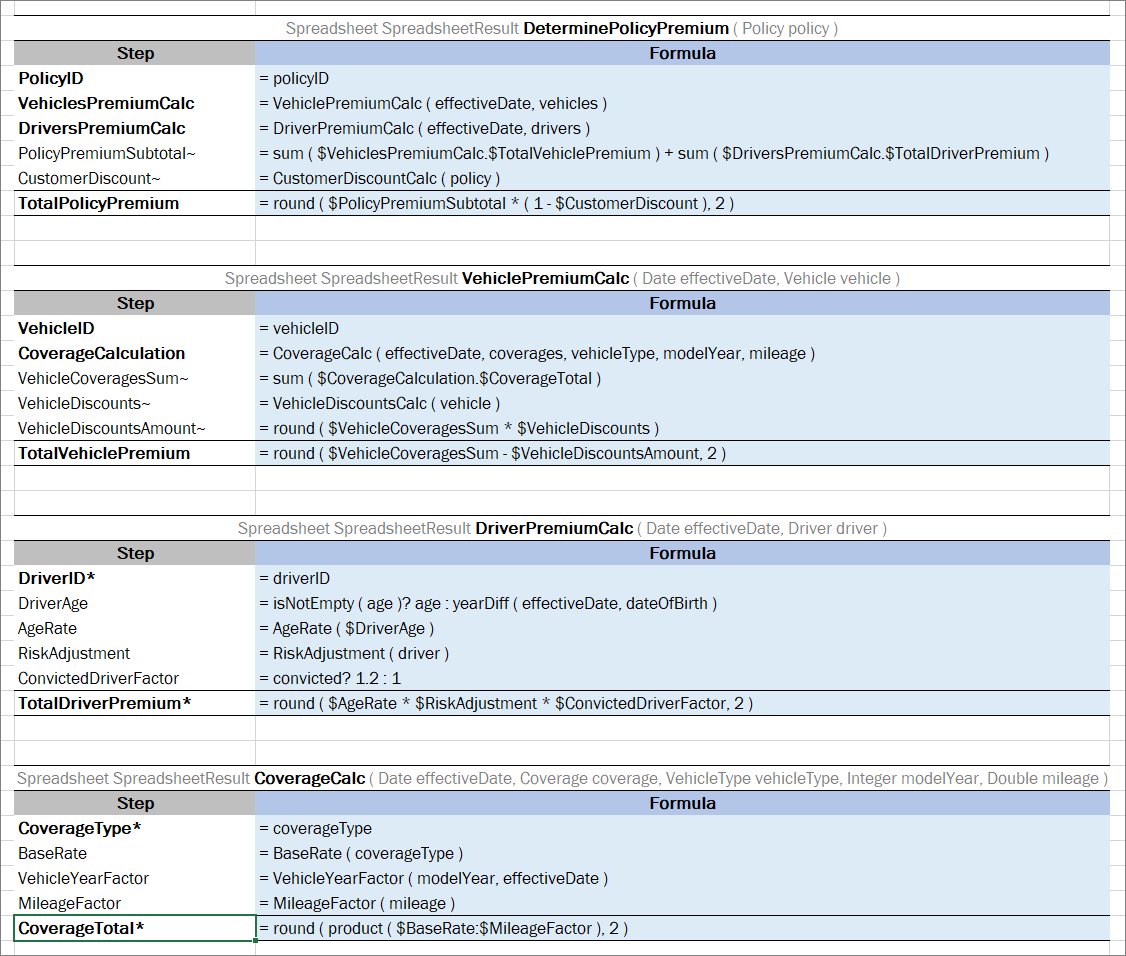
An example of spreadsheets with steps marked to be included and excluded
An output result for these spreadsheets is as follows.
{
"PremiumCalc": {
"PolicyID": "P1",
"VehiclesPremiumCalc": [
{
"VehicleID": "V1",
"CoverageCalculation": [
{
"CoverageType": "Bodily Injury",
"CoverageTotal": 240.98
},
{
"CoverageType": "Property Damage",
"CoverageTotal": 208.85
}
],
"TotalVehiclePremium": 413.83
}
],
"DriversPremiumCalc": [
{
"DriverID": "D1",
"TotalDriverPremium": 1.2
}
],
"TotalPolicyPremium": 365.23
}
}
It is also possible to filter spreadsheet columns identifying the ones to be displayed or hidden in the output result. Use the ~ or * markings depending on whether there are more columns to include or exclude from the final result. The following naming rules apply:
- If a spreadsheet has two columns, the step name in API is RowName.
- If a spreadsheet has more than two columns, the step name in API is ColumnName_RowName.
Note: If there is only one spreadsheet column marked as mandatory, its name in API is just RowName. If there is only one spreadsheet column left after exclusion besides the step column, its name in API is also just RowName.
An example is as follows.
A spreadsheet table with three columns
An output result for this spreadsheet is as follows.
{
"Value_BankID": "commerz",
"Description_BalanceDynamicIndexCalculation": "Calculate Indices B, B1, B2, B3 accoding to Financial Data and Quality Indicators",
"Value_BalanceDynamicIndexCalculation": 0.94,
"Description_BankQualitativeIndexCalculation": "Calculate Indices B, B1, B2, B3 accoding to Financial Data and Quality Indicators",
"Value_BankQualitativeIndexCalculation": 0.9,
"Description_IsAdequateNormativeIndexCalculation": "Calculate Indices B, B1, B2, B3 accoding to Financial Data and Quality Indicators",
"Value_IsAdequateNormativeIndexCalculation": 1,
"Description_BankRating": "Bank Rating R = B x B1 x B2 x B3",
"Value_BankRating": 0.85,
"Description_BankRatingGroup": "Calculate Bank Rating Group",
"Value_BankRatingGroup": "R2",
"Description_LimitIndex": "Calculate Limit Index Kl",
"Value_LimitIndex": 1,
"Description_Limit": "Max Limit which Bank is Allowed\nL = Kl x Lmax",
"Value_Limit": 5000
}
Note that the step names are in the ColumnName_RowName format.
An example of the same spreadsheet with one of the columns excluded using the tilda ~ sign is as follows.
A spreadsheet table with excluded column
An output result for this spreadsheet is as follows.
{
"BankID": "commerz",
"BalanceDynamicIndexCalculation": 0.94,
"BankQualitativeIndexCalculation": 0.9,
"IsAdequateNormativeIndexCalculation": 1,
"BankRating": 0.85,
"BankRatingGroup": "R2",
"LimitIndex": 1,
"Limit": 5000
}
Note that the step names are in the RowName format because there is only one column left besides the Step column.
Now consider the following example that illustrates simultaneous usage of asterix in columns and steps.
A spreadsheet table with filtered columns and steps
An output result for this spreadsheet is as follows.
{
"BankID": "commerz",
"Limit": 5000
}
Note: If the Maven plugin is used for generating a spreadsheet result output model, system integration can be based on generated classes. A default Java package for generated Java beans for particular spreadsheet tables is set using the spreadsheetResultPackage table property. Nevertheless, it is recommended to avoid any integration based on generated classes.
Testing Spreadsheet Result¶
Cells of a spreadsheet result, which is returned by the rule table, can be tested as displayed in the following spreadsheet table.
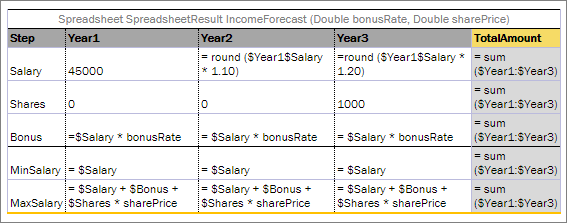
A sample spreadsheet table
Simplified syntax is used to pull results from a spreadsheet table if a spreadsheet table contains only one column besides the row name column:_res_.$<row name>.
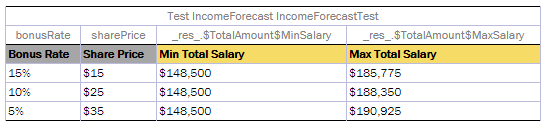
Test for the sample spreadsheet table
Columns marked with the grey color determine income values, and columns marked with yellow determine the expected values for a specific number of cells. It is possible to test as many cells as needed.
The result of running this test in OpenL Studio is provided in the following output table.
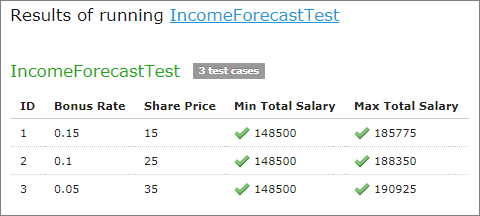
The sample spreadsheet test results
It is possible to test cells of the resulting spreadsheet which contain values of complex types, such as:
- array of values
- custom data type with several attributes
- other spreadsheets nested in the current one
For this purpose, the same syntax described in Specifying Data for Aggregated Objects can be used. It also includes simplified options.
_res_.$<column name>$<row name>[i]
_res_.$<column name>$<row name>.<attribute name>
_res_.$<column of Main Spreadsheet>$<row of Main Spreadsheet>.$<column of Nested Spreadsheet>$<row of Nested Spreadsheet>
_res_.\$\<column of Main Spreadsheet>\$\<row of Main Spreadsheet>[i].\$\<column of Nested Spreadsheet>\$\<row of Nested Spreadsheet>
where i – sequence number of an element, starts from 0.
Consider an advanced example provided in the following figure. The PolicyCalculation spreadsheet table performs lots of calculations regarding an insurance policy, including specific calculations for vehicles and a main driver of the policy. In order to evaluate vehicle and drivers, for example, calculate their score and premium, the VehicleCalculation and DriverCalculation spreadsheet tables are invoked in cells of the PolicyCalculation rule table.
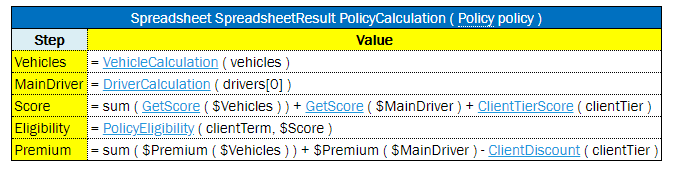
Example of the PolicyCalculation spreadsheet table

Example of the VehicleCalculation spreadsheet table

The advanced sample spreadsheet table
The structure of the resulting PolicyCalculation spreadsheet is rather complex. Any cell of the result can be tested as illustrated in the PolicyCalculationTest test table.

Test for the advanced sample spreadsheet table
To test a spreadsheet that returns a single value, use the same logic as for decision tables.
TBasic Table¶
A TBasic table is used for code development in a more convenient and structured way rather than using Java or Business User Language (BUL). It has several clearly defined structural components. Using Excel cells, fonts, and named code column segments provides clearer definition of complex algorithms.
Important: As this table type is Java code related, TBasic table must not be used unless there is a critical need for it and no other table type can represent the logic in a simpler way more comprehensive for business users.
In a definite UI, it can be used as a workflow component.
The format of the TBasic table header is as follows:
TBasic <ReturnType> <TechnicalName> (ARGUMENTS)
The following table describes the TBasic table header syntax:
| Element | Description |
|---|---|
| TBasic | Reserved word that defines the type of the table. |
| ReturnType | Type of the return value. |
| TechnicalName | Algorithm name. |
| ARGUMENTS | Input arguments as for any executable table. |
The following table explains the recommended parts of the structured algorithm:
| Element | Description |
|---|---|
| Algorithm precondition or preprocessing | Executed when the component starts execution. |
| Algorithm steps | Represents the main logic of the component. |
| Postprocess | Identifies a part executed when the algorithm part is executed. |
| User functions and subroutines | Contains user functions definition and subroutines. |
Column Match Table¶
A column match table has an attached algorithm. The algorithm denotes the table content and how the return value is calculated. Usually, this type of table is referred to as a decision tree.
The format of the column match table header is as follows:
ColumnMatch <ALGORITHM> <return type> <table name> (<input parameters>)
The following table describes the column match table header syntax:
| Element | Description |
|---|---|
| ColumnMatch | Reserved word that defines the type of the table. |
| \<ALGORITHM> | Name of the algorithm. This value is optional. |
| \<return type> | Type of the return value. |
| \<table name> | Valid name of the table. |
| \<input parameters> | Input parameters as for any executable table. |
The following predefined algorithms are available:
| Element | Reference |
|---|---|
| MATCH | MATCH Algorithm |
| SCORE | SCORE Algorithm |
| WEIGHTED | WEIGHTED Algorithm |
Each algorithm has the following mandatory columns:
| Column | Description |
|---|---|
| Names | Names refer to the table or method arguments and bind an argument to a particular row. The same argument can be referred in multiple rows. Arguments are referenced by their short names. For example, if an argument in a table is a Java bean with the some property, it is enough to specify some in the names column. |
| Operations | The operations column defines how to match or check arguments to values in a table. The following operations are available: - match Checks for equality or belonging to a range. The argument value must be equal to or within a range of check values. - min Checks for minimally required value. The argument must not be less than the check value. - max Checks for a maximally allowed value. The argument must not be greater than the check value. The min and max operations work with numeric and date types only. The min and max operations can be replaced with the match operation and ranges. This approach adds more flexibility because it enables verifying all cases within one row. |
| Values | The values column typically has multiple sub columns containing table values. |
The following topics are included in this section:
MATCH Algorithm¶
The MATCH algorithm allows mapping a set of conditions to a single return value.
Besides the mandatory columns, such as names, operations, and values, the MATCH table expects that the first data row contains Return Values, one of which is returned as a result of the ColumnMatch table execution.
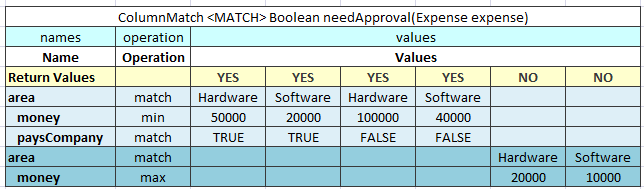
An example of the MATCH algorithm table
The MATCH algorithm works from top to bottom and left to right. It takes an argument from the upper row and matches it against check values from left to right. If they match, the algorithm returns the corresponding return value, which is the one in the same column as the check value. If values do not match, the algorithm switches to the next row. If no match is found in the whole table, the null object is returned.
If the return type is primitive, such as int, double, or Boolean, a runtime exception is thrown.
The MATCH algorithm supports AND conditions. In this case, it checks whether all arguments from a group match the corresponding check values and checks values in the same value sub column each time. The AND group of arguments is created by indenting two or more arguments. The name of the first argument in a group must be left indented.
SCORE Algorithm¶
The SCORE algorithm calculates the sum of weighted ratings or scores for all matched cases. The SCORE algorithm has the following mandatory columns:
- names
- operations
- weight
- values
The algorithm expects that the first row contains Score, which is a list of scores or ratings added to the result sum if an argument matches the check value in the corresponding sub column.
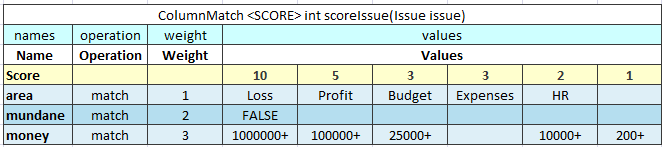
An example of the SCORE algorithm table
The SCORE algorithm works up to down and left to right. It takes the argument value in the first row and checks it against values from left to right until a match is found. When a match is found, the algorithm takes the score value in the corresponding sub column and multiples it by the weight of that row. The product is added to the result sum. After that, the next row is checked. The rest of the check values on the same row are ignored after the first match. The 0 value is returned if no match is found.
The following limitations apply:
- Only one score can be defined for each row.
- AND groups are not supported.
- Any number of rows can refer to the same argument.
- The SCORE algorithm return type is always Integer.
WEIGHTED Algorithm¶
The WEIGHTED algorithm combines the SCORE and simple MATCH algorithms. The result of the SCORE algorithm is passed to the MATCH algorithm as an input value. The MATCH algorithm result is returned as the WEIGHTED algorithm result.
The WEIGHTED algorithm requires the same columns as the SCORE algorithm. Yet it expects that first three rows are Return Values, Total Score, and Score. Return Values and Total Score represent the MATCH algorithm, and the Score row is the beginning of the SCORE part.
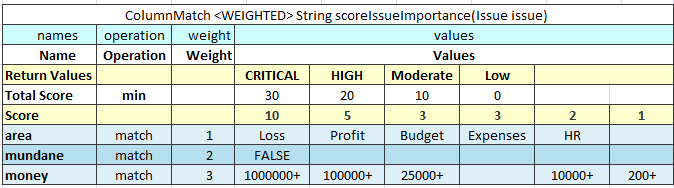
An example of the WEIGHTED algorithm table
The WEIGHTED algorithm requires the use of an extra method table that joins the SCORE and MATCH algorithm. Testing the SCORE part can become difficult in this case. Splitting the WEIGHTED table into separate SCORE and MATCH algorithm tables is recommended.
Constants Table¶
A constants table allows defining constants of different non-custom types. These constants can be then used across the whole project and they do not have to be listed as input parameter in the table header.
An example of a constants table and constants usage is as follows.
Constants table and usage example
In this example, users can create names for some values and use those in rule cells without the “=” symbol. Constants are used in the body of the table but are not listed in the header as input.
The format of the constants table is as follows:
-
The first row is a table header, which has the following format:
Constants \<optional table name>
-
The second row contains cells with a type, name, and value of the constant.
An expression can be used for a constant, for example, 1/3. To define an empty string, use the _DEFAULT_ value.
Table Part¶
The Table Part functionality enables the user to split a large table into smaller parts, or partial tables. Physically, in the Excel workbook, the table is represented as several table parts which logically are processed as one rules table.
This functionality is suitable for cases when a user is dealing with .xls file format using a rules table with more than 256 columns or 65,536 rows. To create such a rule table, a user can split the table into several parts and place each part on a separate worksheet.
Splitting can be vertical or horizontal. In vertical case, the first N1 rows of an original rule table are placed in the first table part, the next N2 rows in the second table part, and so on. In horizontal case, the first N1 columns of the rule table are placed in the first table part, the next N2 columns in the second table part, and so on. The header of the original rule table and its properties definition must be copied to each table part in case of horizontal splitting. Merging of table parts into the rule table is processed as depicted in the following figures.
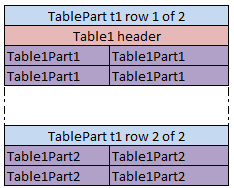
Vertical merging of table parts

Horizontal merging of table parts
All table parts must be located within one Excel file.
Splitting can be applied to any tables of decision, data, test and run types.
The format of the TablePart header is as follows:
TablePart <table id> <split type> {M} of {N}
The following table describes the TablePart header syntax:
| Element | Description |
|---|---|
| TablePart | Reserved word that defines the type of the table. |
| \<table id> | Unique name of the rules table. It can be the same as the rules table name if the rules table is not overloaded by properties. |
| \<split type> | Type of splitting. It is set to row for vertical splitting and column for horizontal splitting. |
| {M} | Sequential number of the table part: 1, 2, and so on. |
| {N} | Total number of table parts of the rule table. |
The following examples illustrate vertical and horizontal splitting of the RiskOfWorkWithCorporate decision rule.
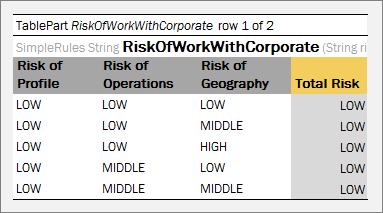
Table Parts example. Vertical splitting part 1
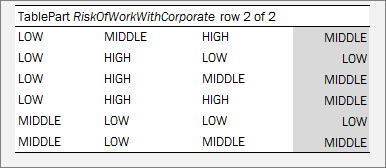
Table Parts example. Vertical splitting part2
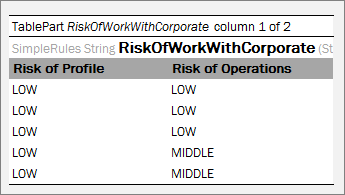
Table Part example. Horizontal splitting part 1
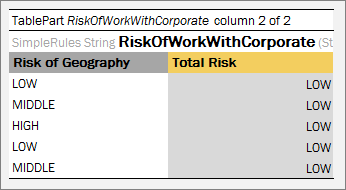
Table Parts example. Horizontal splitting part 2
Table Properties¶
For all OpenL Tablets table types, except for Properties Table, Configuration Table and the Other type tables, that is, non-OpenL Tablets tables, properties can be defined as containing information about the table. A list of properties available in OpenL Tablets is predefined, and all values are expected to be of corresponding types. The exact list of available properties can vary between installations depending on OpenL Tablets configuration.
Table properties are displayed in the section which goes immediately after the table header and before other table contents. The properties section is optional and can be omitted in the table. The first cell in the properties row contains the properties keyword and is merged across all cells in column if more than one property is defined. The number of rows in the properties section is equal to the number of properties defined for the table. Each row in the properties section contains a pair of a property name and a property value in consecutive cells, that is, second and third columns.
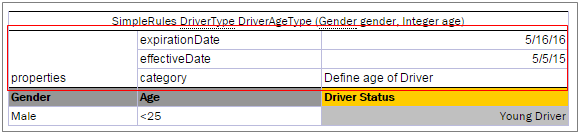
Table properties example
The following topics are included in this section:
- Category and Module Level Properties
- Default Value
- System Properties
- Properties for a Particular Table Type
- Rule Versioning
- Info Properties
- Dev Properties
- Properties Defined in the File Name
- Properties Defined in the Folder Name
- Keywords Usage in a File Name
Category and Module Level Properties¶
Table properties can be defined not only for each table separately, but for all tables in a specific category or a whole module. A separate Properties Table is designed to define this kind of properties. Only properties allowed to be inherited from the category or module level can be defined in this table. Some properties, such as description, can only be defined for a table.
Besides the Properties table, the module level properties can also be defined in a name of the Excel file corresponding to the module. For more information on defining properties in the Excel file name, see Properties Defined in the File Name.
Properties defined at the category or module level can be overridden in tables. The priority of property values is as follows:
- Table.
- Category.
- Module.
-
Default value.
Note: The OpenL Tablets engine allows changing property values via the application code when loading rules.
Default Value¶
Some properties can have default values. A default value is a predefined value that can be changed only in the OpenL Tablets configuration. The default value is used if no property value is defined in the rule table or in the Properties table.
Properties defined by default are not added to the table's properties section and can only be changed in the Properties pane on the right side of OpenL Studio Rules Editor.
System Properties¶
System properties can only be set and updated by OpenL Tablets, not by users. OpenL Studio defines the following system properties:
- Created By
- Created On
- Modified By
- Modified On
For more information on system properties, see OpenL Studio Guide.
Properties for a Particular Table Type¶
Some properties are used just for particular types of tables. It means that they make sense just for tables of a special type and can be defined only for those tables. Almost all properties can be defined for Decision Tables, except for the Datatype Package property intended for Datatype Tables, the Scope property used in Properties Tables, the Auto Type Discovery property used in Spreadsheet Tables, and the Precision property designed for Test Tables.
OpenL Tablets checks applicability of properties and produces an error if the property value is defined for table not intended to contain the property.
Applications using OpenL Tablets rules can utilize properties for different purposes. All properties are organized into the following groups:
| Group | Description |
|---|---|
| Business dimension | Business Dimension Properties |
| Version | Rule Versioning |
| Info | Info Properties |
| Dev | Dev Properties |
Properties of the Business Dimension and Rule Versioning groups are used for rule versioning. They are described in detail further on in this guide.
Rule Versioning¶
In OpenL Tablets, business rules can be versioned in different ways using properties as described in Table Properties. This section describes the most popular versioning properties:
| Property | Description |
|---|---|
| Business Dimension Properties | Targets advanced rules usage when several rule sets are used simultaneously. This versioning mechanism is more extendable and flexible. |
| Active Table | Is more suitable for “what-if” analysis. It allows storing the previous versions of rule tables in an inactive status in a project to track changes or for any other reference. |
Business Dimension Properties¶
This section introduces the Business Dimension group properties and includes the following topics:
- Introducing Business Dimension Properties
- Using Effective and Expiration Date
- Using a Request Date
- Using an Origin Property
- Overlapping of Properties Values for Versioned Rule Tables
- Rules Runtime Context
- Runtime Context Properties in Datatype Tables
Introducing Business Dimension Properties¶
The properties of the Business Dimension group are used to version rules by property values. This type of versioning is typically used when there are rules with the same meaning applied under different conditions. In their projects, users can have as many rules with the same name as needed; the system selects and applies the required rule by its properties. For example, calculating employees’ salary for different years can vary by several coefficients, have slight changes in the formula, or both. In this case using the Business Dimension properties enables users to apply appropriate rule version and get proper results for every year.
The following table types support versioning by Business Dimension properties:
- Decision tables, including rules, simple rules, smart rules, simple lookups, and smart lookup tables
- Spreadsheet
- TBasic
- Method
- ColumnMatch
Note: Test, Datatype, and Data table types cannot be versioned.
When dealing with almost equal rules of the same structure but with slight differences, for example, with changes in any specific date or state, there is a very simple way to version rule tables by Business Dimension properties. Proceed as follows:
-
Take the original rule table and set Business Dimension properties that indicate by which property the rules must be versioned.
Multiple Business Dimension properties can be set.
-
Copy the original rule table, set new dimension properties for this table, and make changes in the table data as appropriate.
- Repeat steps 1 and 2 if more rule versions are required.
Now the rule can be called by its name from any place in the project or application. If there are multiple rules with the same name but different Business Dimension properties, OpenL Tablets reviews all rules and selects the corresponding one according to the specified context variables or, in developers’ language, by runtime context values.
Note: When creating a versioned rule, keep the input parameter name exactly the same as in the original rule. This is required for backward compatibility.
The following table contains a list of Business Dimension properties used in OpenL Tablets:
| Property | Name to be used in rule tables |
Name to be used in context |
Level to define a property at |
Type | Description |
|---|---|---|---|---|---|
| Effective / Expiration dates |
- effectiveDate - expirationDate |
currentDate | Module Category Table | Date | Time interval within which a rule table is active. The table becomes active on the effective date and inactive after the expiration date. Multiple instances of the same table can exist in the same module with different effective and expiration date ranges. |
| Start / End Request dates |
- startRequestDate - endRequestDate |
requestDate | Module Category Table | Date | Time interval within which a rule table is introduced in the system and is available for usage. |
| LOB (Line of Business) |
lob | lob | Module Category Table | String[] | LOB for a rule table, that is, business area for which the given rule works and must be used. |
| US Region | usregion | usRegion | Module Category Table | Enum[] | US regions for which the table works and must be used. |
| Countries | country | country | Module Category Table | Enum[] | Countries for which the table works and must be used. |
| Currency | currency | currency | Module Category Table | Enum[] | Currencies for which the table works and must be used. |
| Language | lang | lang | Module Category Table | Enum[] | Languages for which this table works and must be used. |
| US States | state | usState | Module Category Table | Enum[] | US states for which this table works and must be used. |
| Canada Province | caProvinces | caProvince | Module Category Table | Enum[] | Canada provinces of operation to use the table for. |
| Canada Region | caRegions | caRegion | Module Category Table | Enum[] | Canada regions of operation to use the table for. |
| Region | region | region | Module Category | Enum[] | Economic regions for which the table works and must be used. |
| Origin | origin | Module Category Table | Enum | Origin of rule to enable hierarchy of more generic and more specific rules. |
|
| Nature | nature | nature | Module Category Table | String | Property of any kind holding user-defined business meaning. |
The table properties can be obtained using the following syntax:
| Variable | Description |
|---|---|
| $properties | Returns the object containing all properties of the current table, for example, the effective date of the rules version that OpenL determines according to the context data or effective date of the next rule set if such rule set exists. To access a particular property, use the $properties.usState syntax. |
| $dispatchingProperties | Returns an array of property objects for all tables with the same signature, that is, all tables used in the dispatching logic. |
Example: Use setTime(date,0,0,0,0) for testing endRequestDate or expirationDate as follows: =setTime($properties.endRequestDate, 0, 0,0,0)
Note for experienced users: A particular rule can be called directly regardless of its dimension properties and current runtime context in OpenL Tablets. This feature is supported by setting the ID property as described in Dev Properties, in a specific rule, and using this ID as the name of the function to call. During runtime, direct rule is executed avoiding the mechanism of dispatching between overloaded rules.
For more information on using attributes for runtime context definition, see Runtime Context Properties in Datatype Tables.
Illustrative and very simple examples of how to use Business Dimension properties are provided further in the guide on the example of Effective/Expiration Date and Request Date.
Using Effective and Expiration Date¶
The following Business Dimension properties are intended for versioning business rules depending on specific dates:
| Property | Description |
|---|---|
| Effective Date | Date as of which a business rule comes into effect and produces required and expected results. |
| Expiration Date | Date after which the rule is no longer applicable. If Expiration Date is not defined, the rule works at any time on or after the effective date. If Expiration Date is not defined and several versions of a rule satisfy the context, a rule with the newest effective date is applied. |
The date for which the rule is to be performed must fall into the effective and expiration date time interval.
Users can have multiple versions of the same rule table in the same module with different effective and expiration date ranges. However, these dates cannot overlap with each other, that is, if in one version of the rule effective and expiration dates are 1.2.2010 – 31.10.2010, do not create another version of that rule with effective and expiration dates within this dates frame if no other property is applied.
Consider a rule for calculating a car insurance premium quote. The rule is completely the same for different time periods except for a specific coefficient, a Quote Calculation Factor, or Factor. This factor is defined for each model of car.
The further examples display how these properties define which rule to apply for a particular date.
The following figure displays a business rule for calculating the quote for 2011.The effective date is 1/1/2011 and the expiration date is 12/31/2011.
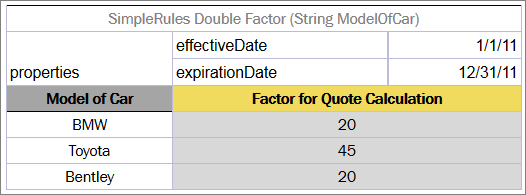
Business rule for calculating a car insurance quote for year 2011
However, the rule for calculating the quote for the year 2012 cannot be used because the factors for the cars differ from the previous year.
The rule names and their structure are the same but with the factor values differ. Therefore, it is a good idea to use versioning in the rules.
To create the rule for the year 2012, proceed as follows:
- To copy the rule table, use the Copy as New Business Dimension feature in OpenL Studio as described in OpenL Studio Guide, Creating Tables by Copying section.
- Change effective and expiration dates to 1/1/2012 and 12/31/2012 appropriately.
- Replace the factors as appropriate for the year 2012.
The new table resembles the following:
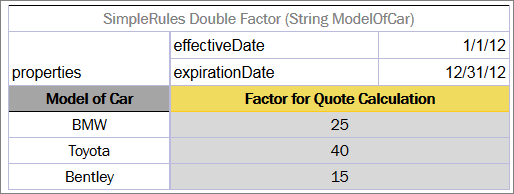
Business rule for calculating the same quote for the year 2012
To check how the rules work, test them for a certain car model and particular dates, for example, 5/10/2011 and 11/2/2012. The test result for BMW is as follows:

Selection of the Factor based on Effective / Expiration Dates
In this example, the date on which calculation must be performed, per client’s request, is displayed in the Current Date column. In the first row for BMW, the current date value is 5/10/2011, and since 5/10/2011>= 1/1/2011 and 10/5/2011\<= 12/31/2011, the result factor for this date is 20.
In the second row, the current date value is 2/11/2012, and since 2/11/2012 >= 1/1/2012 and 2/11/2012 \<= 12/31/2012, the factor is 25.
Using a Request Date¶
In some cases, it is necessary to define additional time intervals for which user’s business rule is applicable. Table properties related to dates that can be used for selecting applicable rules have different meaning and work with slightly different logic compared to the previous ones.
| Property | Description |
|---|---|
| Start Request Date | Date when the rule is introduced in the system and is available for usage. |
| End Request Date | Date from which the system stops using the rule. If not defined, the rule can be used any time on or after the Start Request Date value. |
The date when the rule is applied must be within the Start Request Date and End Request Date interval. In OpenL Tablets rules, this date is defined as a request date.
Note: Pay attention to the difference between the previous two properties: effective and expiration dates identify the date to which user’s rules are applied. These dates usually bear legal meaning and a user refers to them when a definite milestone is achieved, for example, when some business logic or regulations are approved, and the company becomes legally allowed to use it. In contrast, request dates identify when user’s rules are used, or called from the application.
Users can have multiple rules with different start and end request dates, where dates must intersect. In such cases, priority rules are applied as follows:
-
The system selects the rule with the latest Start Request date.
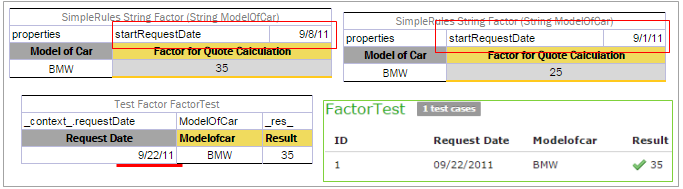
Example of the priority rule applied to rules with intersected Start Request date
-
If there are rules with the same Start Request date, OpenL Tablets selects the rule with the earliest End Request date.
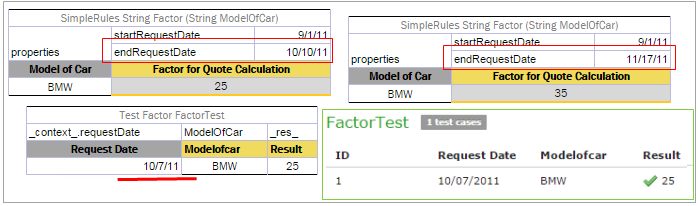
Example of the priority rule applied to the rules with End Request date
If the start and end request dates coincide completely, the system displays an error message saying that such table already exists.
Note: A rule table version with exactly the same Start Request Date or End Request Date cannot be created because it causes an error message.
Note: In particular cases, request date is used to define the date when the business rule was called for the very first time.
Consider the same rule for calculating a car insurance quote but add date properties, Start Request Date and End Request Date, in addition to the effective and expiration dates.
For some reason, the rule for the year 2012 must be entered into the system in advance, for example, from 12/1/2011. For that purpose, add 12/1/2011 as Start Request Date to the rule as displayed in the following figure. Adding this property tells OpenL Tablets that the rule is applicable from the specified Start Request date.
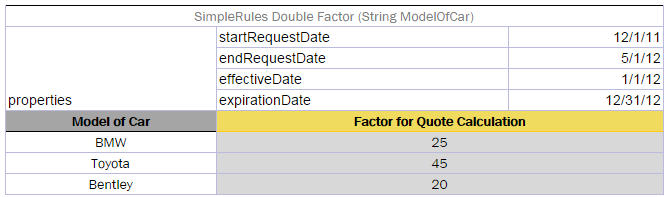
The rule for calculating the quote is introduced from 12/1/2011
Assume that a new rule with different factors from 2/3/2012 is introduced as displayed in the following figure.
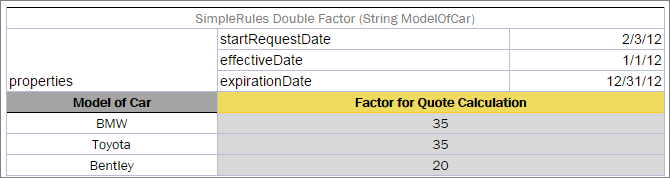
The rule for calculating the Quote is introduced from2.3.2011
However, the US legal regulations require that the same rules for premium calculations must be used; therefore, users must follow the previous rules for older policies. In this case, storing a request date in the application helps to solve this issue. By the provided request date, OpenL Tablets will be able to select rules available in the system on the designated date.
The following figure displays results of testing the rules for BMW for particular request dates and effective dates.

Selection of the Factor based on Start / End Request Dates
In this example, the dates for which the calculation is performed are displayed in the Current Date column. Remember that it is not today’s date. The dates when the rule is run and calculation is performed are displayed in the Request Date column. Request date is the date when the results of the rule call are actually requested.
Pay attention to the row where Request Date is 3/10/2012. This date falls in both start and end Request date intervals displayed in Figure 144 and Figure 145. However, the Start Request date in Figure 145 is later than the one defined in the rule in Figure 144. As a result, correct factor value is 35.
Using Context Variables as Arguments¶
Context variables can be used as input parameters. It is one more way to define context, in addition to using a _context_ object or defining a field in a datatype table.
An example of using a context variable as an argument is as follows:

Using a context variable as an input parameter
Using an Origin Property¶
The Origin Business Dimension property indicates the origin of rules used to generate a hierarchy of more generic and more specific rules. This property has two values, Base and Deviation. A rule with the Deviation property value has higher priority than a rule with the Base value or a rule without property value. A rule with the Base property value has higher priority than a rule without property value. As a result, selecting the correct version of the rule table does not require any specific value to be assigned in the runtime context, and the correct rule table is selected based on the hierarchy.
An example is as follows.
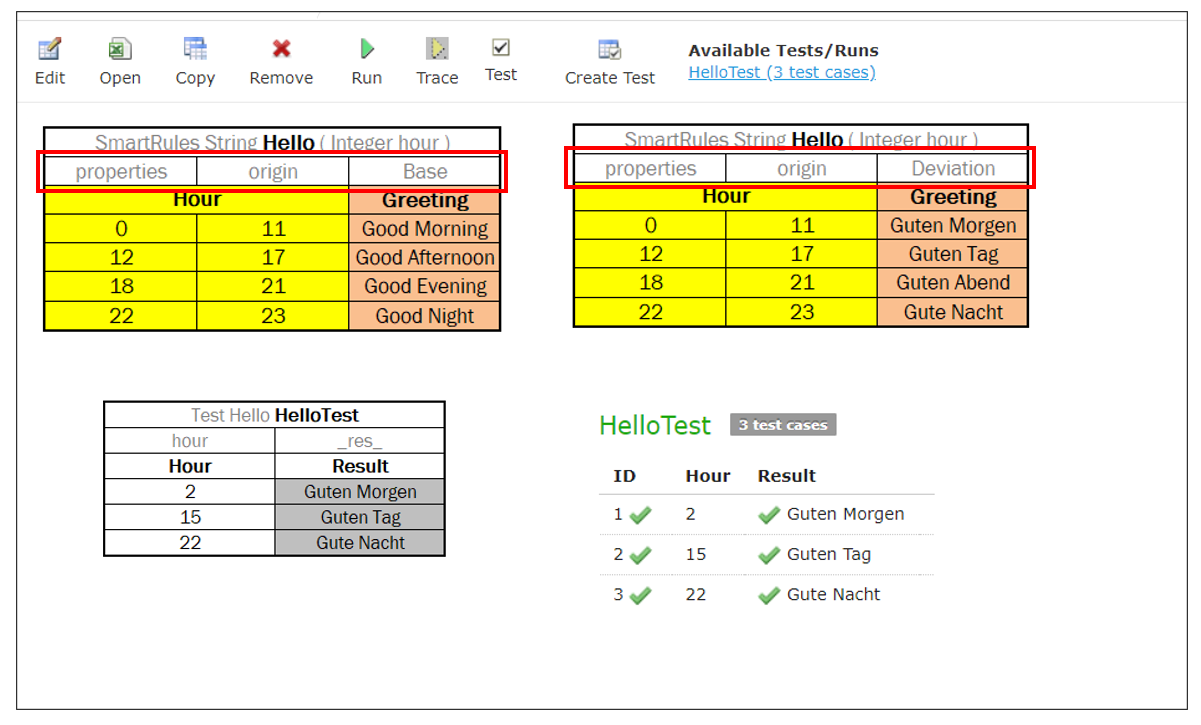
Example Rule table with origin property
Overlapping of Properties Values for Versioned Rule Tables¶
By using different sets of Business Dimension properties, a user can flexibly apply versioning to rules, keeping all rules in the system. OpenL Tablets runs validation to check gaps and overlaps of properties values for versioned rules.
There are two types of overlaps by Business Dimension properties, “good” and “bad” overlaps. The following diagram illustrates overlap of properties, representing properties value sets of a versioned rule as circles. For simplicity, two sets are displayed.
Example of logic for “good” and “bad” overlaps
The No overlap case means that property value sets are totally different and the only one rule table can be selected according to the specified client request in runtime context. An example is as follows:
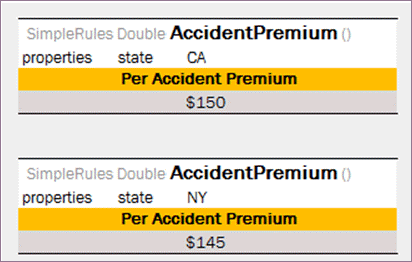
Example of No overlap case
The “Good” overlap case describes the situation when several rule versions can be selected according to the client request as there are intersections among their sets, but one of the sets completely embeds another one. In this situation, the rule version with the most detailed properties set, that is, the set completely embedded in all other sets, is selected for execution.
Note: If a property value is not specified in the table, the property value is all possible values, that is, any value. It also covers the case when a property is defined but its value is not set, that it, the value field is left empty.
Detailed properties values mean that all these values are mentioned, or included, or implied in properties values of other tables. Consider the following example.
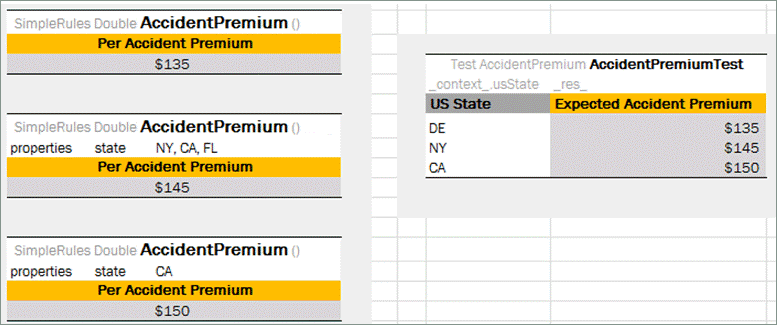
Example of a rule with “good” overlapping
The first rule table is the most general rule: there are no specified states, so this rule is selected for any client request. It is the same as if the property state is defined with all states listed in the table. The second rule table has several states values set, that is, NY, CA, and FL. The last rule version has the most detailed properties set as it can be selected only if the rule is applied to the California state.
The following diagram illustrates example overlapping.
Logic of properties set inclusion
For the Delaware state, the only the first rule is applicable, that is, 135\$ Accident Premium. If the rule is applied to the New York state, then the first and second rule versions are suitable by property values, but according to the “good” overlapping logic, the premium is 145\$ because the second rule table is executed. And, finally, Accident Premium for the California state is 150\$ despite the fact that this property is set in all three rule tables: absence of property state in the first table means the full list of states set.
The “Bad” overlap is when there is no certain result variant. “Bad” overlap means that sets Si and Sj have intersections but are not embedded. When a “bad” overlap occurs, the system displays the ambiguous error message.
Consider the following example.

Example of a rule with “bad” overlapping
For the California state, there are two possible versions of the rule, and “good” overlapping logic is not applicable. Upon running this test case, an error on ambiguous method dispatch is returned.
Note: For the matter of simplicity, only one property, state, is defined in examples of this section. A rule table can have any number of properties specified which are analyzed on overlapping.
Note: Only properties specified in runtime context are analyzed during execution.
Note: Overlapping functionality is not supported for the Date properties.
Rules Runtime Context¶
OpenL Tablets supports rules overloading by metadata, or business dimension properties.
Sometimes a user needs business rules that work differently but have the same input.
Consider provided vehicle insurance and a premium calculation rule defined for it as follows:
PREMIUM = RISK_PREMIUM + VEHICLE_PREMIUM + DRIVER_PREMIUM - BONUS
For different US states, there are different bonus calculation policies. In a simple way, for all states there must be different calculations:
PREMIUM_1 = RISK_PREMIUM + VEHICLE_PREMIUM + DRIVER_PREMIUM - BONUS_1, for state #1
PREMIUM_2 = RISK_PREMIUM + VEHICLE_PREMIUM + DRIVER_PREMIUM - BONUS_2, for state #2
...
PREMIUM_N = RISK_PREMIUM + VEHICLE_PREMIUM + DRIVER_PREMIUM - BONUS_N, for state #N
OpenL Tablets provides a more elegant solution for this case:
PREMIUM = RISK_PREMIUM + VEHICLE_PREMIUM + DRIVER_PREMIUM - BONUS*, where
BONUS* = BONUS_1, for state #1
BONUS* = BONUS_2, for state #2
...
BONUS* = BONUS_N, for state #N
So a user has one common premium calculation rule and several different rules for bonus calculation. When running premium calculation rule, provide the current state as an additional input for OpenL Tablets to choose the appropriate rule. Using this information OpenL Tablets makes decision which bonus method must be invoked. This kind of information is called runtime data and must be set into runtime context before running the calculations.
The following OpenL Tablets table snippets illustrate this sample in action.



The group of Decision Tables overloaded by properties
All tables for bonus calculation have the same header but a different state property value.
OpenL Tablets has predefined runtime context which already has several properties.
Runtime Context Properties in Datatype Tables¶
To simplify runtime context definition, declare it in the Datatype table fields. Mark datatype fields as a context field to be used later in rule versioning.
Use one of the following formats for runtime context properties:
-
<attributeName> : contextIt is used when a model datatype name equals the context variable name.
-
<attributeName> : context.<contextVariable>It is used when a model datatype field name is not equal to the corresponding context variable name.
For more information on the context variable name, see Introducing Business Dimension Properties, the Name to be used in context column in the Business Dimension properties list table.
Consider the following example.
To vary rules by the date when insurance was applied for, create a dedicated runtime context property for it in the model or use the existed one if applicable.
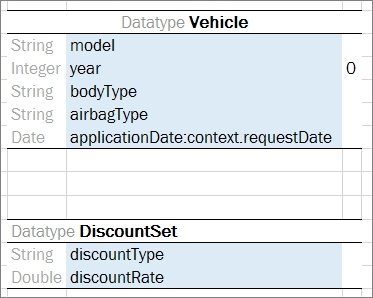
RequestDate set as applicationDate in a datatype table
There are two tables describing discount factors, for different request dates.

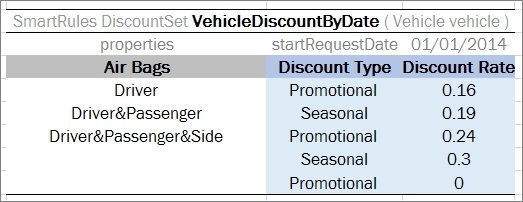
SmartRules tables with data for different request dates
In the test table, use the attribute name specified in the Datatype table. To test the provided cases, use the applicationDate attribute name only.

Test table example
Every time the rule is run, OpenL Tablets consequentially checks the input fields and if a context field is found, it is updated with the corresponding value.
Active Table¶
Rule versioning allows storing the previous versions of the same rule table in the same rules file. The active rule versioning mechanism is based on two properties, version and active. The version property must be different for each table, and only one of them can have true as a value for the active property.
All rule versions must have the same identity, that is, exactly the same signature and dimensional properties values. Table types also must be the same.
An example of an inactive rule version is as follows.
An inactive rule version
Info Properties¶
The Info group includes properties that provide useful information. This group enables users to easily read and understand rule tables.
The following table provides a list of Info properties along with their brief description:
| Property | Name to use in rule tables |
Level at which property can be defined and overridden |
Type | Description |
|---|---|---|---|---|
| Category | category | Category, Table | String | Category of the table. By default, it is equal to the name of the Excel sheet where the table is located. If the property level is specified as Table, it defines a category for the current table. It must be specified if scope is defined as Category in the Properties table. |
| Description | description | Table | String | Description of a table that clarifies use of the table. An example is Car price for a particular Location/Model. |
| Tags | tags | Table | String[] | Tag that can be used for search. The value can consist of any number of comma-separated tags. |
| Created By | createdBy | Table | String | Name of a user who created the table in OpenL Studio. |
| Created On | createdOn | Table | Date | Date of table creation in OpenL Studio. |
| Modified By | modifiedBy | Table | String | Name of a user who last modified the table in OpenL Studio. |
| Modified On | modifiedOn | Table | Date | Date of the last table modification in OpenL Studio. |
Dev Properties¶
The Dev properties group impacts the OpenL Tablets features and enables system behavior management depending on a property value.
For example, the Scope property defines whether properties are applicable to a particular category of rules or for the module. If Scope is defined as Module, the properties are applied for all tables in the current module. If Scope is defined as Category, use the Category property to specify the exact category to which the property is applicable.

The properties are defined for the ‘Police-Scoring’ category
The following topics are included in this section:
Dev Properties List¶
The Dev group properties are listed in the following table:
| Property | Name to be used in rule tables |
Type | Table type | Level at which property can be defined |
Description |
|---|---|---|---|---|---|
| ID | id | Table | All | Table | Unique ID to be used for calling a particular table in a set of overloaded tables without using business dimension properties. Note: Constraints for the ID value are the same as for any OpenL function. |
| Build Phase | buildPhase | String | All | Module, Category, Table | Property used to manage dependencies between build phases. Note: Reserved for future use. |
| Validate DT | validateDT | String | Decision Table | Module, Category, Table | Validation mode for decision tables. In the wrong case an appropriate warning is issued. Possible values are as follows: - on: checks for uncovered or overlapped cases. - off: validation is turned off. - gap: checks for uncovered cases. - overlap: checks for overlapped cases. |
| Fail On Miss | failOnMiss | Boolean | Decision Table | Module, Category, Table | Rule behavior in case no rules were matched: - If the property is set to TRUE, an error occurs along with the corresponding explanation. - If the property is set to FALSE, the table output is set to NULL. |
| Scope | scope | String | Properties | Module, Category | Scope for the Properties table. |
| Datatype Package | datatypePackage | String | DataType | Table | Name of the Java package for generating the data type. |
| Recalculate | recalculate | Enum | Module, Category, Table | Way of a table recalculation for a variation. Possible values are Always, Never, and Analyze. |
|
| Cacheable | cacheable | Boolean | Module, Category, Table | Identifier of whether to use cache while recalculating the table, depending on rule input. |
|
| Precision | precision | Integer | Test Table | Module, Category, Table | Precision of comparing the returned results with the expected ones while launching test tables. |
| Auto Type Discovery | autoType | Boolean | Properties Spreadsheet |
Module, Category, Table | Auto detection of data type for a value of the Spreadsheet cell with formula. The default value is true. If the value is true, the type can be left undefined. |
| Concurrent Execution | parallel | Boolean | Module, Category, Table | Controls whether to parallel the execution of a rule when the rule is called for an array instead of a single value as input parameter. Default is false. |
|
| Calculate All Cells | calculateAllCells | Boolean | Spreadsheet | Module, Category, Table | Returns a particular type. Default is true when calculation is started from the beginning of the spreadsheet. If this property is set to false, calculation is started from the last line of the spreadsheet. |
| Empty Result Processing | emptyResultProcessing | String | Decision table | Module, Category, Table | Identifier of whether to process blank parameter value cells and return an empty result if found, when set to RETURN, or ignore and find the first non-empty result value, when set to SKIP (default). |
The following example illustrates how the property emptyResultProcessing works depending on property values when x=1:
| SmartRules Integer codes(Integer x) | ||
|---|---|---|
| properties | emptyResultProcessing | SKIP |
| X | RESULT | |
| 1-100 | ||
| 1-200 | 3 | |
| 1-300 | 4 | |
| SmartRules Integer codes(Integer x) | ||
|---|---|---|
| properties | emptyResultProcessing | RETURN |
| X | RESULT | |
| 1-100 | ||
| 1-200 | 3 | |
| 1-300 | 4 | |